



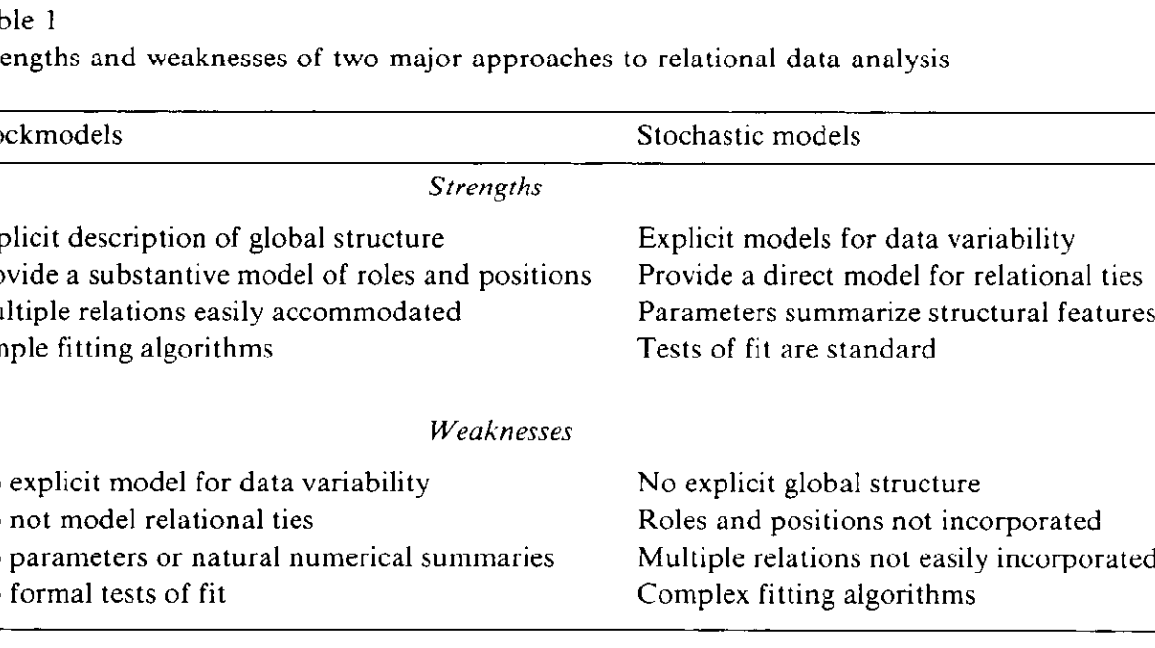
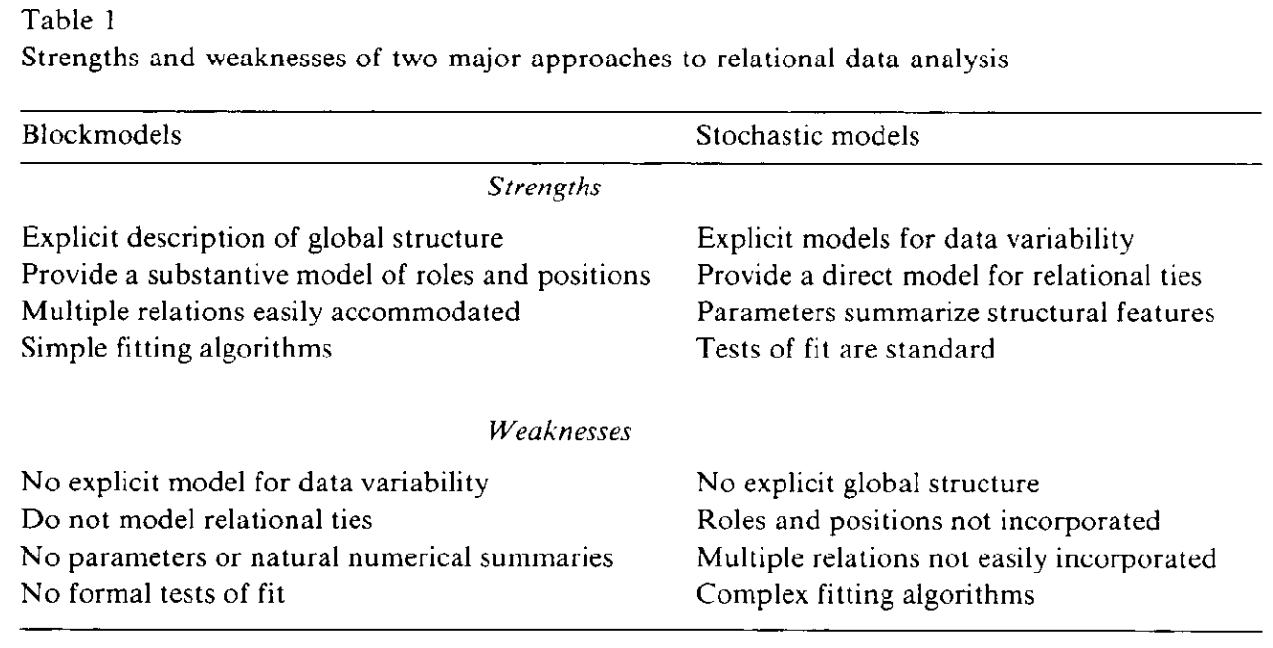
The use of relational data in social science has surged over the past two decades, driven by interest in network structures and their behavioral implications. However, the methods for analyzing such data are underdeveloped, leading to ad hoc, nonreplicable research and hindering the development of robust theories. Two emerging approaches, blockmodels and stochastic models for digraphs, offer promising solutions. Blockmodels clearly describe global structure and roles but lack explicit data variability models and formal fit tests. On the other hand, stochastic models handle data variability and fit testing but do not model global structure or relational ties. Combining these approaches could address their limitations and enhance relational data analysis.
Educational Testing Service and Carnegie-Mellon University researchers propose a stochastic model for social networks, partitioning actors into subgroups called blocks. This model extends traditional block models by incorporating stochastic elements and estimation techniques for single-relation networks with predefined blocks. It also introduces an extension to account for tendencies toward tie reciprocation, providing a one-degree-of-freedom test for model fit. The study discusses a merger of this approach with stochastic multigraphs and blockmodels, describes formal fit tests, and uses a numerical example from social network literature to illustrate the methods. The conclusion relates stochastic blockmodels to other blockmodel types.
A stochastic blockmodel is a framework used for analyzing sociometric data where a network is divided into subgroups or blocks, and the distribution of ties between nodes depends on these blocks. This model formalizes the deterministic blockmodel by introducing variability in the data. It is a specific type of probability distribution over adjacency arrays, where nodes are partitioned into blocks, and ties between nodes within the same block are modeled to be statistically equivalent. The model assumes that relations between nodes in the same block are distributed similarly and independently of ties between other pairs of nodes, formalizing the concept of “internal homogeneity” within blocks.
In practical applications, stochastic blockmodels analyze single-relation sociometric data with predefined blocks. The model simplifies estimation by focusing on block densities the probability of a tie between nodes in specific blocks. The estimation process involves calculating the likelihood function for observed data and deriving maximum likelihood estimates for block densities. This approach is particularly efficient as the likelihood function is tractable, and maximum likelihood estimates can be directly computed from observed block densities. This method allows for calculating measures such as the reciprocation of ties, providing insights into network structure beyond what deterministic models can offer.
The study explores advanced blockmodeling techniques to analyze reciprocity and pair-level structures in social networks. It discusses the concept of reciprocity, where mutual ties in relationships can exceed chance expectations, and introduces the Pair-Dependent Stochastic Blockmodel (PSB), which accounts for dependencies between relations. The Stochastic Blockmodel with Reciprocity (SBR) is a specific case of the PSB that includes parameters for mutual, asymmetric, and null ties. The text also covers estimation using Maximum Likelihood Estimation (MLE) and model fit testing. An empirical example from Sampson’s Monastery data illustrates the practical application of these models.
In conclusion, The excerpt addresses two key topics related to non-stochastic blockmodels. First, it discusses the closure challenge, noting that stochastic blockmodels are not closed under the binary product of adjacency matrices, complicating the understanding of indirect ties. Second, it explores the Bayesian approach to generating blocks, where blocks are not predetermined but discovered from data. This approach specifies the number of blocks, block size distributions, and density parameters for different block types. The Bayesian model allows for posterior probability estimation of block memberships, aiding in a more systematic relational data analysis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
This post was originally published on this site be sure to check out more of their content



