



Abstract
The rapid expansion of digital communication has driven online social networks (OSNs) to surpass conventional news outlets, seamlessly integrating into our daily lives. This dependence on social network data has led to the emergence of various research paths, including event detection. However, such research tasks require large scale labelled social network data, and annotating such vast amounts of data is nearly impractical and often considered unfeasible. In addition, established literature encounters significant hurdles when it comes to detect unseen or new events, even after acquiring a substantial amount of training data. This marks a new era, emphasizing the importance of leveraging minimal data and embracing broader generalizations, much like human understanding of information. To this end, we proposed AttendFew, a model to detect events in X (formely X) with limited data (Few-shot learning) which detects events while mitigating data dependency, even for unseen events, aligning with the current need for less data and greater adaptability. The proposed method encodes the posts (also known as “posts”) with BERTweet and Graph Attention Networks to capture both contextual and structural aspects of social network data and further, stacked attention will be applied to make the model attend local and global context effectively and enhances the ability to understand complex data of social network. Furthermore, the amalgamation of the feature score and Multi-layer Perceptron (MLP) facilitates class matching, aligning the derived features with their associated classifications. This operation emphasizes pivotal dimensions within the feature space while addressing data sparsity. AttendFew is evaluated on real-world datasets and exhibits significantly better performance than state-of-the-art (SOTA) and other baseline methods in terms of accuracy, F1-score. This study represents an attempt to utilize a few-shot learning model in addressing the challenges posed by the sparsity and dynamism of online social networks for event detection.
Introduction
The exponential growth of online social networks has transformed the landscape of news dissemination, allowing users to stay informed with real-time updates, news, and conversations on a wide range of events. This evolution has revolutionized how information is shared and consumed, empowering users to actively participate in shaping the news narrative.
Numerous online social networks, including X, Instagram, and Facebook, coexist, but X stands out as the most popular, boasting millions of monthly active users and a daily influx of millions of posts. The incorporation of features like hashtags and mentions has significantly altered the landscape of information dissemination among users. For example, many events go viral only with the help of hashtags like #Afghanistan #Taliban during the time of Taliban takeover Afghanistan and #FIFAWorldCupQatar2022, where the hashtag was available on social network before the starting of an actual event1.
The widespread availability and heavy reliance on data sourced from online social networks for information gathering have opened up numerous research opportunities. These include tasks such as detecting social bots, instances of hate speech2, rumors3,4 and exploring various other potential applications. One particularly notable research is event detection within online social networks. This process involves distilling valuable insights and enabling informed decision-making in areas including disaster response, public health monitoring, and market analysis. Additionally, event detection serves as a cornerstone for understanding societal trends, shaping policy initiatives, and strengthening public safety measures.
Researchers have approached event detection from various prespectives. In the beginning, linguistic features and statistical methods5,6,7 were explored. As researchers progressed further to supervised techniques, emphasis shifted to neural networks like CNN and RNN, which autonomously learn features from vast datasets, leading to notable performance enhancements. However, these methods encounter several challenges with OSN data, including the necessity for ample labeled data, the complexity of informal language and user-generated content, and the incapacity to adjust to emerging event categories. The authors further shifted towards unsupervised techniques8,9 in an attempt to mitigate the aforementioned limitations, such as difficulty in labeling large datasets and approaches in literature not being able to discover new or unseen events in testing. However, such methods also face challenges ranging from computationally intensive tasks in handling extensive data from online social networks.
Few-shot learning
The concept of few-shot learning (FSL) is based on the observed ability of humans to reason effectively and analyze information well. In 2020, the authors from10 provided an in-depth definition of FSL, encompassing experience, task, and machine learning performance. This definition, widely acknowledged, states: A computer program is considered to learn from experience (Exp) concerning certain classes of task (Task) and performance measure (Per) if its performance can enhance with (Exp) on (Task) as evaluated by (Per). It is important to note that in FSL, the experience (Exp) is limited.
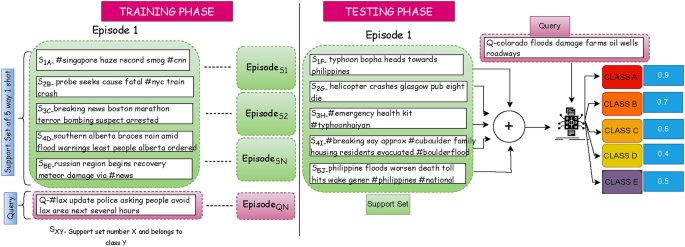
The few-shot learning model is structured around an N-way K-shot methodology, where N signifies the total number of classes, and K represents the number of examples allocated per class. In N-way K-shot classification, the model undergoes iterative training over multiple episodes as depicted in Fig. 1. Each episode consists of one or more training tasks, and model evaluation is conducted using distinct test tasks. Every training task incorporates two datasets. The support set consists of K labeled training samples per class for a total of N classes. The query set includes one or more unseen instances (“query instance”) for each of the N classes. Based on learned representations from the support set, the model classifies each query instance.

Framework illustrating the working process of few-shot learning.
Our contribution
In this study, FSL is introduced to address the shortcomings of conventional event detection methods in online social networks. Inspired by human cognitive abilities, FSL employs minimal data while achieving broader generalization. Unlike conventional classification algorithms, it operates effectively with minimal training instances. It employs a distinct methodology where training and testing samples are sourced from separate sets, also helps in addressing the covariate shift issue commonly encountered in OSN data as shown in Fig. 1. At its core, aligning with the need of the hour, given the exponentially surging real-world online social network data, FSL is an attempt to train models that learn to handle new classes in testing using only a few sets of labeled examples. Our objective is to develop a more robust and adaptable representation capable of seamlessly adjusting to new classes during testing, even if previously unseen. By indentifying patterns and distinguishing features across various classes, Few-shot learning facilitates superior predictions even when data is scarce. This ability to handle new classes with limited data aligns seamlessly with the current requirements of event detection in OSNs. It empowers the model to perform effectively on unfamiliar data, leveraging insights from the support set, despite differences in data distribution between training and testing phases. When dealing with limited data, it’s crucial to carefully consider encoding schemes. Therefore, attention was also directed towards encoding schemes, taking into account the diverse contexts of online social network data. Overall, AttendFew presents a promising approach to enhance event detection in OSNs, addressing challenges associated with traditional methods and enabling more efficient and accurate predictions.
The primary contributions outlined in the article are:
-
With the swift expansion of data on social networks and the challenges of annotating and managing such vast amounts, event detection in online social networks is being redefined through the integration of few-shot learning techniques.
-
Expanding the horizon of event detection in online social networks to encompass unseen events.
-
The primary concern lies in low-resource learning since the task of annotating extensive, diverse, and continually evolving social network data is impractical.
-
An attempt is being made to comprehensively address the diversity and complexity of social network data by managing the various inherent contexts through diverse attentive channels.
-
Empirical validation of the proposed approach over benchmark datasets is done.
-
Additionally, a comprehensive assessment is being conducted through an ablation study to analyze the impact of each component within the model.
Although, few-shot learning has been extensively studied within image classification, its utilization in text-based tasks, notably in natural language processing (NLP), has yet to be thoroughly investigated. To this end, this work seeks to leverage the advantages of FSL to detect events in the unstructured and informal data sourced from online social networks (OSNs).
The remainder of this paper is structured as follows: In Sect. “Related work”, offers a brief review of the existing literature on event detection, particularly in the context of online social networks. Section “Proposed model” describes in detail the operational aspects of the proposed approach. Section “Experimental setup and results” offers a comprehensive explanation of the experimental setup and presents the findings of the evaluation. Finally, Sect. “Conclusion and future work” offers a summary of the findings and puts forward directions for future research.
Related work
The inception of event detection research11 aimed at identifying and pinpointing events in broadcast news streams. With the rise of social networks, there has been an increasing focus on extracting valuable information from these platforms for various purposes. Various researchers, as outlined in surveys by9,12,13,14, have explored different approaches to event detection, spanning unsupervised8,15, supervised, and semi-supervised learning methods. These efforts have highlighted significant challenges in event detection such as the lack of standardized evaluation metrics and benchmark datasets within the domain of online social networks. Early studies by11,16,17 primarily focused on feature engineering, statistical, and linguistic techniques5,16, aimed at identifying previously unknown events. The emergence of deep neural networks18,19 has led many researchers to adopt them for addressing event detection challenges, often framing the problem as a classification task19,20,21.While such approaches notably enhanced performance, it encountered limitations in detecting unknown events that were not present during training.
Moreover, it necessitates a substantial amount of labeled data for training, and the still struggles to identify unseen events. An additional challenge arises from the impracticality of labeling social network data due to its diverse and extensive nature. Managing such vast amounts of data requires extensive computational resources, and time constraints further exacerbate the issue. To address the detection of unseen events, data augmentation strategies have been introduced22.
Few-shot learning (FSL)
While few-shot learning has been extensively explored within the computer vision domain, researchers have also delved into applying this concept to natural language processing (NLP), further expanding its scope and applicability23,24. FSL facilitates the model in acquiring valuable features with minimal reliance on labeled data. Early research efforts were centered on generative transfer learning models, which leveraged pre-trained models for the target task. However, these approaches present challenges for real-world applications25, as they necessitate task-specific designs and often fail to capture the distribution characteristics adequately. The unique nature of short-text data, characterized by its brevity and limited contextual comprehension, poses challenges for many conventional methods, resulting in decreased performance. However, recent years have witnessed notable advancements in few-shot text classification, largely driven by innovations in meta-learning, pretraining, attention mechanisms, and induction networks.
The authors of26 introduced matching networks to map a small labeled support set and an unlabelled example to their respective labels without the need for fine-tuning, thereby accommodating new class types. Furthermore, prototypical networks, as introduced in27, were developed to acquire a metric space by assessing the distance between query and prototype representations for individual classes. After this assesment, the query is allocated to the prototype class that demonstrates the nearest proximity. Metric learning, as explored in26,27,28, calculates the distance between observed classes.
In the domain of newly discovered few-shot tasks such as intention classification, a recent proposal by the authors of26 introduced an adaptive metric learning strategy. This method authomatically determines the optimal weighted combination from a pool of metrics acquired through meta-training tasks.”
Lee et al.29 presented a semi-supervised technique for few-shot text classification, utilizing attention-based lexicon construction. This method enhances the training dataset by employing attention weights derived from long short-term memory (LSTM). Further, the authors from30 proposed DMIN model that offers increased flexibility for memory-based few-shot learning (FSL) through the implementation of dynamic routing. Recently, the concept of a learning quicly, capable of rapidly generalizing new concepts, has emerged in the field of meta-learning31. Recent developments by32 and33 have improved meta-learning based on deep neural networks through the implementation of fine-tuning techniques.
Particularly, Metric learning in few-shot learning has become prominent because of its extensively studied distance function theory and its practical implementation efficiency. Prototype networks in metric learning have achieved state-of-the-art performance on numerous few-shot learning benchmarks. While few-shot learning has been extensively studied in image classification, its application in NLP remains relatively unexplored. To this end, our approach aims to tackle event detection in online social networks through the utilization of a low-resource learning technique called few-shot learning. This approach aims to alleviate the computational burden, address the challenge of limited labeled data, high ambiguity of social network data and expand the scope of event detection to include new categories of events.
Current status and limitations
The current literature on event detection in online social networks lacks exploration of strategies to effectively manage the influx of data amidst limited computational resources. This gap slows the progress in addressing challenges such as computational intensity, data ambiguity, and inability to label enormous amount of social media data. Existing approaches face challenges in adapting to new or unseen event categories with changing contexts. To address this gap, event detection in online social networks through a FSL paradigm, introducing a fresh perspective on the task with the aim of less data and more generalization. Few-shot learning allows models to learn from limited labeled data, thereby reducing the need for annotation of huge data and helps in overcoming the limitations of conventional methods. Moreover, it provides a solution for handling the unstructured and diverse nature of social media data, where traditional supervised learning approaches may struggle. Utilizing few-shot learning enhances the scalability and adaptability of event detection systems to unseen event categories and dynamic contexts. Finally, the comparison of the state-of-the-art methods is summarized in Table 1.
Problem definition
In this few-shot training scenario, a diverse pool of classes (C_{text {Tall}}) exists, each containing multiple examples. The training process involves randomly selecting (N) classes to form a training set. From each selected class, (K) examples are chosen, resulting in a support set (S) comprising (N times K) instances. The remaining examples from each class constitute the query set (Q), which the model predicts. The task, often referred to as the (N)-way-(K)-shot problem, where, (N) represents number of classes and (K) signifies number of instances chosen from (N) classes, aims to classify query instances into one of the (N) classes using information from the support set. The instances within the training set can be organized into a support set, defined as follows:
The support set (S) is represented by pairs ((x_{ak}, c_a)), where (x_{ak}) signifies the (k)th instance in the (a)th class ((C_a)). The query set (Q) consists of instances (q_{b}) and their corresponding classes (C_{b}). The formulation of the query set (Q) is as follows:
In this equation, each (q_{k}^b) represents kth instance belonging to the class (C_b). Consequently, the concept of few-shot event detection can be described as follows:
where, (g({r_{ka}}_{k=1}^{K}, q)) represents a function used to compute the degree of match between the query sentence (q) and ({r_{ka}}_{k=1}^{K}). This study aims to refine the matching function for few-shot event detection. Here, (C_a) denotes a class prototype composed of (K) sentences from the support set (S). Unlike conventional prototypical networks, which treat all sentences uniformly, this model introduces an attention-guided prototype, highlighting the encoder’s importance, especially in data-scarce scenarios. Algorithm 1 outlines the proposed methodology. In the algorithm, (C) represents the total number of examples in the training set. (C_T) is the total number of classes. (C_{text {epi}}) denotes the number of classes per episode. (N_s) is the number of support instances per class. The function RandomSample(S, C) randomly selects (C) elements from the set (S). Detailed explanation of the workflow is provided in the following sections.

Attentive few-shot learning
Proposed model
This section offers a comprehensive overview of our proposed approach, named AttendFew. It comprises several key steps, such as Instance Attentive Encoding, Attention-guided Prototype Model, and Aggregated Class Matching. Figure 2 illustrates the overall architecture. Furthermore, detailed explanation of each functional component are provided in the subsequent subsections.

Workflow of the proposed ATTendFew framework.
Instance attentive encoding
Instance attentive encoding transforms posts into meaningful representations, even with limited samples. Diverse encoding mechanisms enable comprehensive modeling of OSN data from multiple perspectives, capturing context more effectively. To enhance feature extraction and capture both inter and intra-tweet dynamics, two complementary attention channels are introduced, ensuring a comprehensive understanding from a limited dataset.
Instance attentive content–context channel
This attentive channel involves transforming support set posts into comprehensible representations by leveraging BERTweet for tweet analysis. It provides a dual advantage, aiming to extract contextual tweet representations while also incorporating self-attention mechanisms to capture information across multiple abstraction levels.
BERTweet35, a masked language model based on BERT, is tailored to handle the complexities of X data, including casual language, unstructured content, and X-specific elements like hashtags and emoticons. Hashtags, crucial for event dissemination, are retained during preprocessing to ensure data reliability. BERTweet excels in understanding the linguistic and contextual nuances of X, enhancing its interpretative abilities. It has been successfully applied to tasks like hate speech detection and identifying political bias, consistently outperforming in English text classification36,37,38.
In few-shot learning, where training data is limited, BERTweet’s advanced techniques are vital for effective learning from small datasets. While BERT’s Transformer architecture excels at understanding word context in both directions, challenges persist in effectively handling and representing unstructured social network data.
By utilizing self-attention, BERTweet seamlessly captures contextual information throughout the input sequence. A tweet (t) containing raw text with (n) words ((P)) will be converted into vector form using the BERTweet model, as described in Eqs. (5) and (4).
Here, TweetB represents the embedded tweet, which belongs to ({mathbb {R}}^{d}), where (d) represents the dimensionality of the vector.
Instance attentive syntactic–context channel
The motivation for constructing this additional channel arises from the observation that the syntactic information in the final layer of BERT is limited. Therefore, it becomes imperative to develop an additional network that improves the posts understanding of comprehensive syntactic information. The objective is to capture every aspect of the data thoroughly and extract as much information as possible, considering the limited availability of samples. In this study, we utilize the graph attention network to establish the channel, which involves two key components: creating a graph and employing GAT for analysis39.
-
The motivation behind constructing this graph is to capture the dynamics between posts and prioritize their contributions to the prototype. With limited samples and varying tweet importance, it’s crucial to extract meaningful information from each tweet, including hashtags, which significantly influence the event. The attention mechanism in GAT enhances interpretability by revealing patterns, establishing connections, and deriving insights from few samples in vast online social networks. This approach also aids in interpreting the extensive and unstructured information on platforms like X.
-
Graph attention network: In this module, exploration into understanding posts is conducted. Each tweet (T = {p_1, p_2, ldots , p_n}) comprises a collection of (n) words intricately connected together, generating a narrative that is uniquely its own.
To obtain insights from such a network of connections, exploration of what is known as a tweet graph (G = (V, E)) is necessary. This network comprises nodes representing individual words as (V) and edges as (E) indicating the relationships between them. Considering the graph (G = (V, E, R)), the concept of directed dependencies comes into play with nodes v and edges ((v_i, ell , v_j) in E), where (ell in R) signifies a dependency relation. Each connection between nodes acts as a bridge, guiding comprehension from one word to another. These directed dependencies deepen analysis, revealing intricate details within the tweet’s structure.
In this intricate network, recurring words stand out as key focal points, each holding significance in the narrative. Additionally, hashtags serve as markers, leads to imporatnt topics. The vertices of the graph also include hashtags, and features are extracted using the BERTweet model. The input for the structural passage is defined below:
In the context of graph attention networks (GAT), L typically represents the number of layers in the network. Each layer in the GAT processes the input graph data iteratively, allowing the model to capture contextual details both at a local and global level for a given tweet and its associated context as described in below Eq. (8).
The method for updating the feature aggregation of a particular node z at layer L involves considering the set of neighboring nodes denoted as NN(z), as stated in Eq. (9).
The default number of attention heads is set to 1 as a deliberate choice, considering the brevity of the text and to avoid unnecessary complexities. (La_{j}^{l-1}) signifies the representation of the j-th node at the ((l-1))-th layer. The attention score after normalization between nodes z and j in layer l, denoted as (alpha _{l}^{zj}), is articulated as described in Eq. (10).
Where (s(cdot )) represents the scaled dot-product attention function, acknowledged for its superior efficiency compared to alternative attention mechanisms due to its optimal utilization of matrix products. The calculation for computing this function is described in the subsequent Eq. (11).
where (W_{l}^{p}) and (W_{l} in {mathbb {R}}^{d} times d) are trainable parameter matrices.
Each word representation (La_z) undergoes iterative updates across GAT layers by aggregating information from neighboring nodes, enabling the multilayer GAT to capture dependencies among distant words. Utilizing this property, the Stacked Attention mechanism is utilized to combine the features extracted from different GAT layers, as demonstrated in Eq. (12), with the intuition that not all layers contribute equally, and attention should be focused on the layers that contain more valuable information, highlighting its essential function. By stacking multiple attention layers, the model first attends to fine-grained linguistic features and then refines its focus on broader event structures. This allows for more effective event detection, even with limited labeled examples, by leveraging both local and global contextual cues. Subsequently, a max-pooling operation, elaborated in Eq. (13), is applied to select prominent features for generating node embedding as output. This entire process can be expressed as follows:
Where, (alpha _z) is a trainable parameter that acts as a weight, balancing the contribution of the (text {GAT}^{ztext {th}}{text {Layer output}}) and adhering to the constraint (sum {z=1}^{L} alpha _z= 1).
Attentive dynamic context-driven fused prototype
In this subsection, information from the two attentive channels is combined to select informative instances (posts) from the support set using an attention mechanism. The intution behind this approach is the acknowledgment that not all instances in the support set are equally important. Simply averaging the information from all instances, as commonly done in vanilla prototype27, represented in Eq. (14) may not be the most effective strategy.
Here, (Proc_{text {a}}) denotes the prototype for a class (C_a), computed from the instances of the support set (S) belonging to that class. (tw_a) represents the total number of posts in the support set of class (C_a), and ((t_a^j)) signifies the embedding of tweet (j).
To this end, a two-stage implementation of an attentive dynamic context-driven fused prototype is proposed. Initially, information from both channels is merged, followed by the application of an attention mechanism to the vanilla prototype.
Dynamic context-driven fusion
A dynamic fusion mechanism merges information from the Instance attentive content–context and syntactic–context channels. This adaptive mechanism learns optimal fusion strategies during training by adjusting weights based on the quality and relevance of the data, eliminating the reliance on fixed parameters. The model prioritizes informative content, enhancing performance while reducing the impact of less relevant information. Over time, the model improves its ability to assign fusion weights, leading to continual refinement. The proposed approach begins by computing a dynamic weight matrix, (gamma), which is derived from the correlation between outputs of the two channels. A sigmoid activation function is applied to confine the values of (gamma) to the range of 0 to 1. The matrix (gamma) has dimensions [s, 2d], where ’s’ is the batch size and ’d’ is the output dimension of the passages. (gamma) is then split into two components, (gamma _1) and (gamma _2), each with dimensions [s, d]. Finally, these components, (gamma {1}) and (gamma {2}), are multiplicatively applied to the respective outputs of the two channels in a sequential manner. The calculation process is as mentioned in Eqs. (15)–(17).
In this context, (odot) represents the element-wise dot product, (sigma) denotes the sigmoid activation function, the parameter matrix (W_c) is of size (2d times d), while the bias vector (bc) belongs to ({mathbb {R}}^d).
Attention-guided prototype
Attention mechanisms improve intelligence of the model by focusing on key information and ignoring irrelevant data, unlike traditional systems. They enhance feature representation and context, especially in few-shot learning where data is limited.
Instance-level attention
Instance-level attention assigns relevancy scores to highlight key posts, while sentence-level attention collects informative posts for classification. A feed-forward neural network computes attention scores based on feature similarity to a context vector, refining relevant posts. Inspired by40, this approach improves classification by focusing on significant features and ignoring irrelevant ones, thus enhancing the overall data quality. The feature representation, denoted as (f_{fe}), undergoes processing through a feed-forward neural network to generate an encoded form, as outlined in Eq. (18). Subsequently, the similarity between (f_{fe}) and a context vector (f_w) is computed using the dot product, with (f_w) being randomly initialized and fine-tuned during training. The attention score (alpha _j) of each tweet fe-th instance is then computed using the softmax function, following Eq. (19). Finally, the attention-based representation of each tweet (a_t) is obtained by computing the weighted sum of the hidden representations, as detailed in Eq. (20).
Finally, Eq. (14) is replaced with Eq. (20).
Aggregated class matching
The functionality of this module involves acquiring the attributes of class prototypes and query instances, thus enabling the classification procedure. The accurate classification of a query instance into a specific class depends heavily on how class matching is performed and which distance function is utilized for measurement. These aspects have a significant impact on the effectiveness of prototypical networks.The conventional prototypical network, which exclusively employs the Euclidean distance function as mentioned in Eq. (21).
In the vanilla prototype approach, the distance function (text {dist}(.,.)) measures the distance between two vectors: the class prototype and the query tweet. The authors of27 have advocated for the use of Euclidean distance in this calculation, demonstrating its effectiveness over alternative distance metrics in the context of a prototype network.
The traditional prototypical network assigns equal weight to every feature of an instance, which may not reflect real-world scenarios accurately. In reality, not all features carry the same level of importance; some features contribute more significantly than others. To this end, the integration of two separate functions is utilized to evaluate the similarity between two instances: a Multilayer Perceptron (MLP) and a weighted Euclidean distance. To determine how closely a query instance Q aligns with a class prototype (Proc_{a}), a calculation method is employed. This method, detailed in Eq. (22), utilizes both the query instance and the class prototype to generate a matching score.
The alternative approach employs a weighted Euclidean distance strategy, allowing our model to adapt to data scarcity in few-shot scenarios. Dimensions that exhibit greater prominence and distinctiveness within the feature space are prioritised by introducing weights to the distance function as caculated in Eq. (23). These weights, denoted as (W_a) , are computed as illustrated in Fig. 3:
Employing an MLP for class matching demonstrates enhanced performance compared to the basic Euclidean distance function as shown in Sect. “Ablation study”. Furthermore, to refine the original Euclidean distance function, additional weighting is incorporated. By amalgamating these two distinct functions, the classification accuracy is significantly improved. Finally, MLP is coupled with a weighted Euclidean distance approach for class matching., as defined in Eq. (24).

Extraction of weighted class features.
Experimental setup and results
This section offers an comprehensive overview of the experimental details of the AttendFew model. It encompasses a concise summary of the dataset, parameters, and evaluation metrics. Furthermore, the section delves into the examination of evaluation results, performs a comparative analysis and conducts an ablation study to analyze the affect of individual modules.
Dataset and parameters
Acquiring labeled datasets in Online Social Networks (OSNs) is challenging due to the impracticality of manually labeling vast amounts of data. Additionally, publicly accessible datasets often provide only tweet IDs, leading to data loss when IDs correspond to deleted or removed posts. The AttendFew model is evaluated using two real-world tweet datasets focused on disaster events: CrisisLexT26 and CrisisLexT6 (combined as DS1) and Kaggle & Archive (DS2).
DS1 includes posts from 26 and 6 disaster events, respectively, named CrisisLex26 and CrisisLex6. Each tweet is annotated for source, type, relevance, and informativeness, with a focus on relevant and informative posts during evaluation. To ensure balanced representation, 400 English posts per event were selected, filtering out non-English posts from events like the 2013 Venezuela refinery incident. After filtering, DS1 consists of 18 events from CrisisLexT26 and 2 from CrisisLexT6, totaling 20 events with 400 English posts each. The second dataset is curated from significant global events, such as the Taliban’s takeover of Afghanistan and the FIFA World Cup 2022. It includes 14 events, with ten sourced from Kaggle and four from15. Details are provided in Table 2. The data is split into training, validation, and testing sets in a 60%-20%-20% ratio. Crucially, in the few-shot learning framework, there is no overlap of classes between the training, validation, and testing sets.
-
Pre-processing Data preprocessing is essential, particularly for posts which often include noise like slang and casual language. The process involves removing punctuation, URLs, reposts, duplicates, digits, whitespace, and irrelevant content. Non-English posts are excluded, and the rest are converted to lowercase. Stop-words are then eliminated using spaCyFootnote 1.
-
Hyper-parameters The model, implemented in Python 3.10 using PyTorch, incorporates graph functionality using Networkx. Evaluation is performed across various N-way K-shot scenarios: 2-way, 3-way, and 4-way, with 5-shot, 10-shot, and 15-shot variations. Additionally, unseen events are considered entirely new (i.e., no prior knowledge of similar events exists). Optimal hyper-parameters are determined through experiments, testing different optimizers and learning rates. Training runs for 3000 iterations with validation every 1500 steps, and testing over 1000 iterations. A summary of all hyper-parameters is provided in Table 3.
Performance and evaluation metrics
The performance of the suggested model is evaluated using four commonly used measures: precision, recall, F-score, and accuracy. Precision is determined by how many correct positive predictions are made compared to all positive predictions, including both correct and incorrect ones. Recall seeks that how many correct positive predictions are made compared to all actual positive instances. Precision is particularly important when the focus is on reducing the number of false positives, while recall is more relevant when minimizing false negatives is the priority. The F1-score gives a balanced assessment by combining with harmonic mean precision and recall into a single metric. Lastly, accuracy measures how many predictions are correct out of all predictions made. These metrics are applied to assess the model’s performance, as depicted in Eqs. (25)–(28), respectively.
In the given context:
-
TP (True Positives) denotes the overall count of accurately classified event posts.
-
FP (False Positives) signifies the total number of inaccurately classified event posts.
-
TN (True Negatives) indicates the total count of correctly classified non-event posts.
-
FN (False Negatives) refers to the total number of incorrectly classified non-event posts.
Evaluation results and comparative analysis
The performance metrics are carefully selected to evaluate the model’s effectiveness. While accuracy measures correct predictions, it overlooks the impact of false positives and negatives. Therefore, the F1 score, balancing precision and recall, is included for a more comprehensive evaluation across classes. This section summarizes the performance outcomes of the proposed model using real-world datasets. DS1 is evaluated for 2-way, 3-way, and 4-way classifications, while DS2 is assessed for 2-way and 3-way configurations due to class limitations for training, validation, and testing. A comparative assessment with state-of-the-art (SOTA) methods is also presented, following a brief overview of existing SOTA models.
-
Meta-FCS34: In this approach, unidentified samples are classified based on cosine similarity to class centroids. The method represents short texts by combining word embeddings with word-level topic information, merging local semantics with broader topics for a comprehensive text representation.
-
KA-Proto41: The authors propose a knowledge-aware event detector that uses external knowledge to identify events, even with limited examples. By incorporating diverse semantic relationships, the method enriches short text information. Event detection is approached as a text classification task using a few-shot learning framework.
-
Prototypical Networks27: The authors introduced prototype networks based on metrics for few-shot learning. These networks rely on the idea that we can describe each class by calculating the average of its examples within a representation space that is developed by training a neural network.
-
Proto-HATT42: In this study, the authors proposed hybrid attention-based prototypical networks designed specifically for the complex task of noisy few-shot relation classification. These hybrid attentions consist of two different attentions.
The comparative performance of our approach against state-of-the-art methods is shown in Tables 4, 5, and 6, where our method outperforms others. Table 4 presents comparative results for the 2-way setting with 5, 10, and 15 shots. Similarly, Table 5 reports results for the 3-way setting with the same shot counts. Further, Table 6 shows results for the 4-way setting, again with 5, 10, and 15 shots. Incorporating attentive contexts significantly enhances contextual representation, especially with limited data. These results highlight advanced learning capabilities and effectiveness of the model in improving event detection, even with few samples, while also addressing challenges specific to X data. The informal and unstructured nature of posts challenges models designed for structured data, highlighting the need for adaptable models. A key insight is the significant role of the encoder in initial processing. Integrating transformer-based architectures like BERTweet with graph attention networks shows promising improvement by combining pre-trained models and graph structures, enhancing event detection with limited data. BERTweet’s adaptation for X, particularly in handling unique elements like hashtags, enables effective contextual understanding. Additionally, by prioritizing important instances with attention mechanisms, our approach filters out noise and focuses on the most impactful features.
Ablation study
An ablation study is conducted to verify the efficacy of the proposed model. The analysis involves assessing the influence of each module within the approach and observing the corresponding changes in the evaluation metrics. In the domain of few-shot learning, where data availability is limited, the encoding quality assumes significant importance. As a result, the performance of both encoders is carefully evaluated. Finally, the effectiveness of the class matching module is analyzed. The following variants are considered in this analysis:
-
AttendFew with CNN encoder: utilizes a CNN encoder to highlight the importance of encoders in comprehending textual context. CNN is chosen due to its widespread usage in literature.
-
AttendFew/Content Attention: In the second scenario, BERTweet is omitted, leaving only node attention for evaluation. This allows us to evaluate the effectiveness of each encoder in capturing contextual information.
-
AttendFew/Structural Attention: In the third scenario, we exclude GAT and solely capture content context.
-
AttendFew/Average Class Matching: In the final scenario, class matching relies solely on the Euclidean distance, similar to the approach used in the vanilla prototypical method. This setup allows for evaluating the effectiveness of incorporating module average class matching with MLP (Multi-Layer Perceptron) and weighted Euclidean distance.
The study evaluates four critical modules to assess their effectiveness. Firstly, it examines the impact of the encoder by comparing tweet encodings using a CNN, as commonly found in the literature, with our approach. Figure 4a and b illustrate the support set instances encoded by our approach and CNN, respectively. Figure 4 evaluates a 4-way-5-shot task, where each mark represents a tweet from the support set, with different colors indicating distinct events. posts encoded by our approach 4a show greater clustering compared to CNN 4b, indicating that our encoder captures sentence semantics more effectively.

Visualization of sentence encoding with different approaches.
Furthermore, the impact of content attention and context is evaluated by removing the BERTweet encoder. Given the informal nature of online social networks and the challenges of low-resource learning, capturing content context is crucial. Tables 7 and 8 show that this removal has the most significant impact across scenarios, highlighting the importance of content context for accurate analysis of unstructured X data.
Additionally, the removal of syntactic context notably affects model performance, as shown in Tables 7 and 8. Syntactic dependencies are vital for understanding word relationships within posts, enriching data analysis by providing deeper insights into the platform’s concise and informal language. Incorporating both syntactic and semantic information enhances the ability of the model to extract meaning from limited samples, emphasizing the need to consider both aspects when analyzing X data. In the final scenario, Euclidean distance is used for class matching, similar to the approach in vanilla prototypical networks. However, as shown in Tables 7 and 8, incorporating MLP and weighted Euclidean distance significantly improves performance of the model. This enhancement is due to the recognition that different features carry varying degrees of influence. The weighted Euclidean distance effectively captures these variations, leading to more accurate classifications. Visualizations of loss and accuracy trends are also provided for both the Euclidean distance and the average class matching methods. Figure 5a shows the loss and accuracy trends for the average class matching method, illustrating how the loss fluctuates during training and the accuracy trend on the validation set in DS1. Likewise, Fig. 5a presents these trends for DS2. The average class matching method shows a faster reduction in loss and a more rapid increase in accuracy compared to the Euclidean distance, as illustrated in Fig. 5.

A comparison of accuracy and loss for both methods is conducted on DS1 and DS2 using 2-way 5-shot.
Conclusion and future work
This study addresses event detection in online social networks, focusing on overcoming the challenges of annotating vast amounts of data and the limitations of traditional methods in detecting new/unseen events, even with ample training data. The aim is to use a limited dataset with few samples and enhance generalization to accurately detect new/unseen events across diverse online social networks.
The proposed model emphasizes attentive tweet encoding as a crucial element in data representation. Two contexts are explored: BERTweet, fine-tuned on X data, captures context by leveraging X-specific features, including hashtags and mentions, while the graph attention network comprehends the syntactic information in unstructured data. An attention-guided prototype module then applies attention mechanisms to instances and features, prioritizing those with richer information and context. This approach acknowledges that not all instances and features are equally significant. Training and testing with different data distributions in few-shot learning effectively detect unseen events and also helps to mitigate the covariate shift issue in dynamic social network data. Results show that the model outperforms existing methods on unstructured and informal social network data. Future efforts will focus on adapting the model for industrial applications and extending it to other platforms. Modifications in feature extraction and domain adaptation can enhance its ability to detect novel events across diverse OSNs.
Data availibility
The code generated in the present work is with Sielvie Sharma and may be supplied upon a reasonable request.
References
-
Gupta, S. & Kundu, S. Interaction graph, topical communities, and efficient local event detection from social streams. Expert Syst. Appl. 232, 120890 (2023).
-
Gashroo, O. B., Mehrotra, M., Wani, M. A. & Elaffendi, M. Captain: Capsule network integrated with multilingual transformer for textual abusive content detection in online social networks. IEEE Access 13, 29644–29659 (2025).
-
El Bhih, A., Yaagoub, Z., Rachik, M., Allali, K. & Abdeljawad, T. Controlling the dissemination of rumors and antirumors in social networks: A mathematical modeling and analysis approach. Eur. Phys. J. Plus 139(2), 1–23 (2024).
-
Khanday, A. M. U. D., Wani, M. A., Rabani, S. T. & Khan, Q. R. Hybrid approach for detecting propagandistic community and core node on social networks. Sustainability 15(2), 1249 (2023).
-
Chenliang, L., Aixin, S. & Datta, A. Twevent: Segment-based event detection from tweets. In Proceedings of the 21st ACM international conference on Information and knowledge management 155–164 (2012).
-
Morabia, K., Murthy, N.L.B., Malapati, A. & Samant, S. Sedtwik: Segmentation-based event detection from tweets using wikipedia. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Student research workshop 77–85 (2019).
-
Hettiarachchi, H., Adedoyin-Olowe, M., Bhogal, J. & Gaber, M. M. Embed2Detect: Temporally clustered embedded words for event detection in social media. Mach. Learn. 111(1), 49–87 (2022).
-
Sharma, S., Abulaish, M. & Ahmad, T. KEvent–A semantic-enriched graph-based approach capitalizing bursty keyphrases for event detection in OSN. In 2022 IEEE/WIC/ACM international joint conference on web intelligence and intelligent agent technology (WI-IAT) 588–595 (IEEE, 2022).
-
Atefeh, F. & Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 31(1), 132–164 (2015).
-
Wang, Y., Yao, Q., Kwok, J. T. & Ni, L. M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 53(3), 1–34 (2020).
-
Ji, H. & Grishman, R. Refining event extraction through cross-document inference. In Proceedings of ACL-08: Hlt 254–262 (2008).
-
Lai, V. D. Event extraction: A survey. Preprint at arXiv:2210.03419 (2022).
-
Hasan, M., Orgun, M. A. & Schwitter, R. A survey on real-time event detection from the twitter data stream. J. Inf. Sci. 44(4), 443–463 (2018).
-
Mottaghinia, Z., Feizi-Derakhshi, M.-R., Farzinvash, L. & Salehpour, P. A review of approaches for topic detection in twitter. J. Exp. Theor. Artif. Intell. 33(5), 747–773 (2021).
-
Sharma, S., Abulaish, M. & Ahmad, T. contenxt: A graph-based approach to assimilate content and context for event detection in OSN. IEEE Trans. Comput. Soc. Syst. 11, 5483–5495 (2024).
-
Ahn, D. The stages of event extraction. In Proceedings of the workshop on annotating and reasoning about time and events 1–8 (2006).
-
Hong, Y., Zhang, J., Ma, B., Yao, J., Zhou, G. & Zhu, Q. Using cross-entity inference to improve event extraction. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies 1127–1136 (2011).
-
Nguyen, T. & Grishman, R. Graph convolutional networks with argument-aware pooling for event detection. In Proceedings of the AAAI conference on artificial intelligence32 (2018).
-
Liu, S., Chen, Y., Liu, K. & Zhao, J. Exploiting argument information to improve event detection via supervised attention mechanisms In Proceedings of the 55th annual meeting of the association for computational linguistics (Vol, 1: Long Papers) 1789–1798 (2017).
-
Chen, Y., Xu, L., Liu, K., Zeng, D. & Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) 167–176 (2015).
-
Lai, V. D. & Nguyen, T. H. Extending event detection to new types with learning from keywords. Preprint at arXiv:1910.11368 (2019).
-
Deng, S., Zhang, N., Kang, J., Zhang, Y., Zhang, W. & Chen, H. Meta-learning with dynamic-memory-based prototypical network for few-shot event detection. In Proceedings of the 13th international conference on web search and data mining 151–159 (2020).
-
Wang, F. et al. Cornerstone network with feature extractor: A metric-based few-shot model for Chinese natural sign language. Appl. Intell. 51, 7139–7150 (2021).
-
Howard, J. & Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th annual meeting of the association for computational linguistics 328–339 (2018).
-
Thrun, S. Is learning the n-th thing any easier than learning the first?. Adv. Neural Inf. Process. Syst.8, https://proceedings.neurips.cc/paper_files/paper/1995/file/bdb106a0560c4e46ccc488ef010af787-Paper.pdf (1995).
-
Vinyals, O. et al. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst.29, https://proceedings.neurips.cc/paper/2016/file/90e1357833654983612fb05e3ec9148c-Paper.pdf (2016).
-
Snell, J., Swersky, K. & Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst.30 (2017).
-
Koch, G., Zemel, R., Salakhutdinov, R. et al. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop2, (Lille, 2015).
-
Lee, J.-H., Ko, S.-K. & Han, Y.-S. Salnet: Semi-supervised few-shot text classification with attention-based lexicon construction. In Proceedings of the AAAI conference on artificial intelligence35, 13189–13197 (2021).
-
Geng, R., Li, B., Li, Y., Zhu, X., Jian, P. & Sun, J. Induction networks for few-shot text classification. In Proceedings of the 58th annual meeting of the association for computational linguistics 1087–1094 (2020).
-
Han, X., Zhu, H., Yu, P., Wang, Z., Yao, Y., Liu, Z. & Sun, M. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. Preprint at arXiv:1810.10147 (2018).
-
Sharma, S., Abulaish, M. & Ahmad, T. Probe—A bertweet-attentive prototype few-shot model for event detection in OSN. In 2023 IEEE international conference on web intelligence and intelligent agent technology (WI-IAT) 72–79 (IEEE, 2023).
-
Liu, W., Pang, J., Li, N., Yue, F. & Liu, G. Few-shot short-text classification with language representations and centroid similarity. Appl. Intell. 1–12 https://link.springer.com/article/10.1007/s10489-022-03880-y (2022).
-
Liu, W., Pang, J., Li, N., Yue, F. & Liu, G. Few-shot short-text classification with language representations and centroid similarity. Appl. Intell. 53(7), 8061–8072 (2023).
-
Qudar, M. M. A. & Mago, V. Tweetbert: A pretrained language representation model for twitter text analysis. Preprint at arXiv:2010.11091 (2020).
-
Garg, T., Masud, S., Suresh, T. & Chakraborty, T. Handling bias in toxic speech detection: A survey. ACM Comput. Surv. 55(13s), 1–32 (2023).
-
Barrón-Cedeño, A. et al. The clef-2023 checkthat! lab: Checkworthiness, subjectivity, political bias, factuality, and authority. In European conference on information retrieval 506–517 (Springer, 2023).
-
DeLucia, A., Wu, S.,. Mueller, A., Aguirre, C., Resnik, P. & Dredze, M. Bernice: A multilingual pre-trained encoder for twitter. In Proceedings of the 2022 conference on empirical methods in natural language processing 6191–6205 (2022).
-
Velickovic, P. et al. Graph attention networks. Stat 1050(20), 10–48550 (2017).
-
Yang, Z., Yang, D., Dyer, C., He, X., Smola, A. & Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: Human language technologies 1480–1489 (2016).
-
Guo, J., Huang, Z., Xu, G., Zhang, B. & Duan, C. Knowledge-aware few shot learning for event detection from short texts. In ICASSP 2023 – 2023 IEEE international conference on acoustics, speech and signal processing (ICASSP) 1–5 (2023). https://doi.org/10.1109/ICASSP49357.2023.10095891
-
Gao, T., Han, X., Liu, Z. & Sun, M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In Proceedings of the AAAI conference on artificial intelligence33, 6407–6414 (2019).
Acknowledgements
The authors would like to acknowledge the support of Prince Sultan University for paying the Article Processing Charges (APC) of this publication.
Author information
Authors and Affiliations
Contributions
S.S: Conceptualization, Methodology, Implementation, Validation, Original draft preparation. T.A.: Idea discussion, Paper structure design, Supervision, Writing – review & editing, Result analysis. N.A.W.: Paper structure design, Validation, and Result analysis. N.A.: Conceptualization, Results Discussion. S.A.: Idea discussion, Paper structure design, Result analysis.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sharma, S., Ahmad, T., Wani, N.A. et al. An attention-enhanced few-shot model for event detection in online social networks.
Sci Rep 15, 14764 (2025). https://doi.org/10.1038/s41598-025-97970-9
-
Received:
-
Accepted:
-
Published:
-
DOI: https://doi.org/10.1038/s41598-025-97970-9
Keywords
This post was originally published on this site be sure to check out more of their content



