



Abstract
During the Covid-19 pandemic, the widespread use of social media platforms has facilitated the dissemination of information, fake news, and propaganda, serving as a vital source of self-reported symptoms related to Covid-19. Existing graph-based models, such as Graph Neural Networks (GNNs), have achieved notable success in Natural Language Processing (NLP). However, utilizing GNN-based models for propaganda detection remains challenging because of the challenges related to mining distinct word interactions and storing nonconsecutive and broad contextual data. In this study, we propose a Hierarchical Graph-based Integration Network (H-GIN) designed for detecting propaganda in text within a defined domain using multilabel classification. H-GIN is extracted to build a bi-layer graph inter-intra-channel, such as Residual-driven Enhancement and Processing (RDEP) and Attention-driven Multichannel feature Fusing (ADMF) with suitable labels at two distinct classification levels. First, RDEP procedures facilitate information interactions between distant nodes. Second, by employing these guidelines, ADMF standardizes the Tri-Channels 3-S (sequence, semantic, and syntactic) layer, enabling effective propaganda detection through related and unrelated information propagation of news representations into a classifier from the existing ProText, Qprop, and PTC datasets, thereby ensuring its availability to the public. The H-GIN model demonstrated exceptional performance, achieving an impressive 82% accuracy and surpassing current leading models. Notably, the model’s capacity to identify previously unseen examples across diverse openness scenarios at 82% accuracy using the ProText dataset was particularly significant.
Similar content being viewed by others

Introduction
In the past decade, social media has significantly amplified the dissemination of fake news, propaganda, and misinformation, posing threats to broadcasting, the economy, politics, healthcare, and climate change1. During the COVID-19 pandemic, social media witnessed a surge in misinformation and propaganda. Misinformation, which is unintentionally spread, and propaganda, which deliberately targets emotions to influence opinions, were prevalent. This wave of misleading content, often hidden within articles from various sources, significantly impacts public discussion and opinion sharing2.
Research background
Propaganda is defined as the actions aimed at influencing individuals or groups to achieve specific goals by shaping their actions or beliefs2, whereas disinformation is intentionally spreading false information, while misinformation unintentionally disseminates inaccurate content. During the Covid-19 pandemic, social media witnessed a surge in propaganda, particularly in public discourse on social media3. By employing deliberate rhetorical and psychological tactics, propaganda strategically influences opinions by utilizing techniques such as flag waving, tapping into intense national sentiments, and Loaded Language, which evokes strong emotions. In addition, these techniques can incorporate logical fallacies, such as appeal to authority (falsely claiming someone is an expert), bandwagon fallacies (using flawed reasoning to persuade), and strawman fallacies (distorting an individual viewpoint)2. Nevertheless, many propaganda techniques require a comparison with third-party sources of knowledge, including the approach referred to as card stacking4. For instance, three samples of propaganda and non-propaganda in news articles are shown in Fig. 1. In this paper, primary methods that are usually examined deeply are addressed, with no proof retrieved from other sources of knowledge such as the Internet. Propaganda differs from rumor detection in that it may not rely on misleading information. Instead, it strategically highlights certain facts or evokes emotional reactions, making its identification more challenging5. Propaganda has emerged as a powerful instrument for shaping ideas, effectively reaching large audiences6, and highlighting the need to precisely recognize distinct propaganda techniques7.

Sample instances of propaganda and non-propaganda in news articles.
Additionally, some representation-learning-based approaches aim to model the consistency and variability between modalities in order to extract sentiment cues. In the propaganda detection task, previous studies utilized deep learning models to perform text classification, including Bidirectional Encoder Representations from Transformers (BERT)8, Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs)9,10,11. Nevertheless, all these approaches primarily emphasize the proximity and order of local word words, resulting in a deficiency of long-range and non-adjacent word associations11. Researchers have focused on GNNs, proposing hierarchical graph contrastive learning frameworks to explore complex intra- and inter-modal relationships12. The study of flexible GNNs makes sense when it relates to propaganda detection. Currently, there is limited research on this topic. The inclusion of a variety of propaganda techniques, such as logical fallacies, doubt, and repetition9, presents several challenges when using existing GNN-based methods for detecting propaganda. Propaganda detection benefits from multilevel13, task-based neural architectures trained on Graph Convolutional neural Networks (GCN) for sentence analysis14, as well as SpanBERT, which integrates three jointly trained classifiers for sentences, start, and end points15. Despite promising progress, current work generally focuses on fusing multimodal representations within a single instance, neglecting the specific global co-occurrence characteristics of individual instances. Effectively utilizing feature co-occurrences across instances and capturing the global characteristics of graph-based data remain significant challenge16.
Motivation and research problem of study
In the quest to capture the intricate relationships among nodes throughout the coarsening and refining processes of node representations, recent methodologies have delved into mining the propaganda technique instances within the textual context17,18. HMIGCN17 and HGCL18 exemplify approaches aimed at hierarchical graph coarsening to reduce the size of multimodal convolutional networks for text classification. Notably, HMIGCN proposes a hierarchical multigranularity interaction for document-level classification, in which three different granularity graphs are constructed hierarchically (i.e., section, sentence, and word), thereby enhancing the discriminative power of features17, while HGCL computes the discrete embedding representation of each modality, which includes the global co-occurrence features of each modality18. These methodologies typically execute iterative coarsening and mining processes to modernize global–local graph representations. However, graph learning faces limitations owing to the linear nature of the embedding function, which restricts the capture of complicated designs involving both global and local node basic data, while also necessitating hierarchical information aggregation during training to propagate information across graph edges. On the other hand, we introduce a layer-based structure, such as the intra-inter-layer, wherein coarsening and mining techniques are executed within the intra-layer to modify nodes, whereas links are established within the interlayer to encompass the relations concerning diverse layers.
To rectify this limitation, we propose multilayer RDEP procedures for enhanced node information propagation, following the principles of the Graph-based Hierarchical Feature Integration Network (G-HFIN)18. Initially, graph-based models can further refine the weight of edge connections based on the predetermined graph configuration within intra-graph layers19,20. Here, nodes with analogous configurations in the graph levels are amalgamated as hypernodes to broaden the scope of modernization, whereas the latter are generated as hypernodes over the base graph and are connected to their child segment nodes using relation edges. Subsequently, the interlayers were nonlinearly linked, thus refining the upper- and lower-layer coarsened graph18,21. This direct mapping of information from the upper layer facilitates gradual augmentation of the information volume. Consequently, it facilitates information exchange among distantly connected nodes, preserving both the global and local node data. This optimization of the model’s structure and parameters also reduces the training time.
In addition, capturing various word dependencies in propaganda news by enhancing the attributes across distinct text graphs presents a significant challenge. Existing methods for detecting propaganda focus on extracting features from concealed propaganda news to construct textual-based graphs, such as TGCN17, which focuses on local co-occurrence relationships but may miss high-order word interactions. TensorGCN22 builds third-order text graph tensors but may not appropriately prioritize different features during inter-graph propagation, leading to limitations in capturing the diverse dependencies between words. However, these techniques prioritize unique characteristics to balance inconsistent data across networks through inter-graph transmission. The multiple characteristics have varying degrees of relevance. However, conventional collaborative approaches do not account for these characteristics. In addition, many methods struggle to capture the various word dependencies. As a result, we created three concurrent channels, sequence, semantic, and syntactic (3S), with a variety of characteristics for inter-graph transmission. A refined enhanced feature technique is provided for intragranular graph diffusion inside each channel.
To overcome this limitation, we proposed intra-granular graph propaganda detection approaches, such as ADMF, accounting for varying significance among pairwise features extracted from textual differences to capture diverse text features. The views of the sequential channel, dynamically adjusting the weight reflecting neighbors to capture complementarity, and the rank of syntactic and semantic representations were assigned to each sequence node, followed by a node-wise attention-based method to consolidate these representations. The resulting enhanced matrix is then used to update sequential word dependencies through message passing. Similar procedures were applied to construct syntactic and semantic-enhanced channels. ADMF harmonizes syntactic, semantic, and sequence information across the three channels, thereby enhancing intragranular graph data propagation.
Research contribution
In this paper, we proposed a Hierarchical Graph-based Integration neural Network (H-GIN), designed for detecting propaganda in text within a defined domain using multilabel classification. H-GIN is extracted to build bi-layer graphs inter-intra channels, such as RDEP, and ADMF with suitable labels at two distinct classification levels, which aim at encoding the global information of the language, then feed the word embedding and graph embedding fuse to a self-attention encoder in RoBERTa. Specifically, RDEP procedures facilitate information interactions between distant nodes, whereas ADMF standardizes three sequence (3S) layers, such as sequence, semantic, and syntactic information, enabling effective propaganda detection through related and unrelated information propagation and subsequent pooling of news representations into a classifier.
The specific contributions of this study are as follows.
-
We designed a new hierarchical H-GIN framework for extracting propaganda instances at both local and global levels. This framework leverages intra-graph information, including RDEP techniques, to enhance the propagation of the node statistics. Using refined and coarsened graphs within layers and nonlinear connections between the upper and lower layers promotes gradual information augmentation and exchange among distantly connected nodes. This optimized model structure and parameter tuning also reduce training time.
-
In the graph contrast learning-based multimodal analysis task, we introduced ADMF methods for intragranular graph information diffusion. These methods consolidate sequence, semantic, and syntactic information through weighted representations and node-wise attention strategies across three channels to enhance overall propagation efficiency. Comparative analyses with techniques such as RoBERTa variants, GNN, LSTM, conditional random fields (CRF), and n-grams validate the strength of our methodology, particularly in the context of COVID-19 discourse.
-
The current research accurately curated a comprehensive dataset of Covid-19-related discourse, drawing from propaganda text (ProText) data and various social media platforms such as Facebook and Twitter. The rigorous labeling process, which identifies various propaganda techniques, establishes a robust foundation for subsequent analysis and sets a high standard for data-driven research within the IS community.
-
The experimental results demonstrate that our method outperforms the baseline models, thereby proving its effectiveness. Additionally, ablation studies and result analysis helped us understand the functioning of our model and identify the sources of performance gains.
The remaining of this study is organized as follows. Section “Related Works” discusses “related works that mainly introduce two aspects of research: graph neural network, propaganda detection and classification analysis, and contrastive learning. Section “Material and Methods” “Material and Method” provides a detailed description of the proposed H-GIN architecture and describes the training process of hierarchical graph contrastive learning. Section “Experiments and Results Analysis” “Experiments and Results Analysis” posited the experimental tuning, baseline model, and hyper-parameter description, and conducted comparative experiments between baseline and H-GIN models, as well as ablation study and visualization of experimental results. Finally, Section “Conclusion, Limitations, and Future Directions” “Conclusion, Limitations, and Future Directions” reviews all the findings and draws conclusions.
Related works
In general, propaganda is regarded as a form of communication that motivates or propagates a certain perspective using insufficient evidence and persuasive techniques23,24. Propaganda detection may be considered a challenge for classifying nodes within a graph using GNNs9. Several scholarly contests and exercises, such as SemEval-2020 Task 1125, EMNLP 202226, and NLP4IF2, have included intricate challenges for propaganda technique classification of textual content on social media. In this study, we utilized the suggested enhanced fine-tuning deep learning models for propaganda detection. Thus, in the linked study, we primarily address two aspects: graph neural network and propaganda detection.
Graph-based representations network
Heterogeneous graph attention networks (HGAT)
In addition, short-text classification has been extensively studied for news tagging to enhance search strategies and improve information retrieval results27,28. However, most existing research focuses on long-text classification, resulting in subpar performance on short texts owing to data sparsity and insufficient labeled data. Thus, Heterogeneous Graph Attention Networks (HGAT) are used to embed the HIN for short-text classification by employing a dual-level attention mechanism that includes both node- and type-level attentions29. Moreover, Graph Attention Networks (GATs) address these issues by assigning varying importance to nodes and incorporating memory fusion mechanisms30. Gated GNN (GGNN), compared to sequence-based models using gated recurrent units (GRU), enable inductive learning and overcome over-smoothing problems. Despite their success, there remains a dearth of research on propaganda detection using GNNs, and current models struggle to update node states iteratively and capture diverse word interdependencies crucial for propaganda techniques. Moreover, Wang et al.31 introduced a novel approach called the Knowledge-driven Multimodal GCN (KMGCN) to model semantic representations for fake news detection. However, the KMGCN only extracts visual words as visual information and fails to fully utilize the global information of the image. In contrast, Khademi32 proposed a new neural network architecture known as the Multimodal Neural Graph Memory Network (MNGMN) for Visual Question Answering (VQA). This model constructed a visual graph network based on bounding boxes; however, it resulted in overlapping parts that might provide redundant information.
Graph convolutional networks (GCNs)
Recently, GCNs have attracted significant attention for semi-supervised classification. The TGCN17 model represents an entire text corpus as a document-word graph and employs GCNs for classification purposes. However, these methods focus primarily on long texts and do not use attention mechanisms to capture important information.
In addition, GNNs have been instrumental in text classification, with various models such as HIS-MSA30, TensorGCN22, and TGCN17, which enhance classification accuracy through graph-based representations. HIS-MSA30 integrates features from heterogeneous graph convolution with in-domain self-supervised multitask learning for multimodal sentiment analysis, whereas subsequent models such as TensorGCN22 enhance classification accuracy through propagation learning, and TGCN17 models the whole text corpus as a document-word graph and applies GCN for classification. However, all these methods focus on long texts. It constructs an unrelated graph using syntactic reliance material, augmenting the representation with effective sentiment nodes to enhance dependency parser accuracy. For a large corpus, the aforementioned GCN-based models developed a distinct graph. However, challenges persist in capturing contextual word relations within documents and avoiding oversmoothing effects.
To solve the above problems, Text-level GCN33 creates individual graphs for each input text, allowing the learning of text-level word interactions through a message-passing mechanism. While the GCN model is a special form of Laplacian smoothing to represent adjacent nodes34, potentially resulting in feature over-smoothing with excessive convolutional layers, the CPG-like GCN35 incorporates layers with pre-trained CodeBERT and hybrid neural network models.
Propaganda detection and classification
Propaganda detection at multiclass multilabel
Multimodal learning has surfaced as a strategy for identifying propaganda tactics. For example, Vosoughi et al.36 introduced the multiview propaganda (M-Prop) approach, which integrates a fundamental neural architecture inspired purely by an attention system, eliminating recurrence, and used a transformer-based multiview approach to detect textual material. Tallón-Ballesteros37 used the multimodal propaganda detection analysis (MPDES) model to gather semantics related to sentiments. Feng et al.11 refined a model that enhances each category of techniques by incorporating multimodal pre-trained language models (PLMs) with rich visual features. In addition, Chen et al.38 developed the MViTO-GAT model, which uses attention-based sequential intra-modality and cross-modality graph reasoning to learn lexical and positioning links between visual and textual items.
However, these techniques primarily concentrate on the amalgamation of multimodal characteristics, whereas the identification of memes necessitates greater reasoning among modalities to represent implicit semantic connection39. Consequently, their capacity to extract supplementary data from a multimodal milieu is restricted. Second, although merging multimodal characteristics is emphasized40, there is a lack of logical perception across modalities to represent latent semantic linkages. Finally, as noted by Dimitrov et al.39 multimodal propaganda detection is a component of a visual task. However, the datasets currently available for this purpose are insufficient, with the majority of studies relying only on publicly accessible datasets. The lack of data makes multimodal propaganda identification more difficult, which makes textual modality the most frequently used detection method. In this study, we developed a novel ML-MC classification method using propagation data. This study employs a graph-based network, specifically H-GIN, to detect propaganda in text within a specific domain using multilabel classification. H-GIN constructs a bi-layer graph integrating inter- and intra-channel information using techniques such as RDEP and ADMF for enhanced detection capabilities.
Sentence level classification (SLC) of textual propaganda
More recently, studies have shifted to fine-grained analysis, especially in finding propaganda occurrences at SLC41,42. Deep learning algorithms, such as those used in previous studies, have been utilized to identify propaganda. For example, Abrams and Greenhawt43 emphasized the function of social media in fostering efficient risk communication during the pandemic. On the other hand, Dewantara et al.44 proposed tying a variation to the value of the 1-dimensional Convolutional Neural Network (Conv1D) hyperparameters to determine if propaganda-related spans or fragments exist. Volkova et al.42 obtained textual linguistic components from propaganda detection tasks by training neural network models on tweet and social media interactions, which outperformed lexical models supplemented with linguistic elements. To develop word vector representations, a residual bidirectional LSTM with pre-trained language models and ELMO embeddings is employed, and by training a bidirectional LSTM on particular task data, ELMO incorporates contextual information. Previous studies have investigated numerous methods for identifying propaganda strategies in texts. Martino et al.9 used fine-grained analysis to detect fragments using promotional methods and persistent word linkages. Li and Xiao46 used BERT models combined with multigranular analysis to detect and classify propaganda at the document level. Their method entails fine-tuning BERT-BiLSTM from end to end using a unified loss function, including syntactic and pragmatic information from Linguistic Inquiry and Word Count (LIWC) at the word, sentence, and document levels. Paraschiv et al.47 suggested a BERT-based approach to identify spans and classify strategies using a specific corpus. This model includes a bespoke 768-dimensional dense layer above the final transformer block and a Conditional Random Fields (CRF) layer with binary labels. Moreover, Chernyavskiy et al.48 used RoBERTa for text tokenization, combining token-level feature vectorization for propaganda detection with a simple classifier such as Logistic Regression.
Deep learning models, particularly neural network architectures like BERT, LSTM, and RoBERTa, are effective at capturing sequential context but face challenges in recognizing connections between distant words. This is important when examining various rhetorical devices used in propaganda. These models often emphasize word order and proximity, and sometimes neglect relationships with non-adjacent words, which is crucial for analyzing propaganda strategies49. Subsequently, the large number of parameters in transformer-based models makes them susceptible to overfitting, particularly in situations with limited training data. This impairs the ability of the models to generalize to new test sets50. Finally, biases are exacerbated by dataset imbalances that draw attention to popular strategies, such as name-calling and loaded language, which might misidentify subtler and less-prevalent propaganda techniques51.
Propaganda detection at document-level
Propaganda was mostly detected at the document level through linguistic contents, such as news items, and its definition utilized non-scientific approaches in the past12. According to Volkova et al.45, a neural network model including language infusion was proposed for classifying tweets as either confirmed or questionable. Tweet text and social media were used for this strategy. Among other language-related features of articles, Covid-19 public debates. The focus of current research has switched to sophisticated methods for identifying document-based propaganda, such as Proppy and character n-grams, particularly when applied to Internet news items21. Unseen examples were tested in the identification procedure using a training set. Even when unique labels were absent from the pieces, those that originated from certain news topics were almost always regarded as propaganda45. Nevertheless, studies show that propagandistic media outlets can also post non-propagandistic information52. Occasionally, impartial media outlets may distribute propaganda to further political agendas5. Therefore, it may not always be reliable to classify articles based only on the labels of the news items they include.
Material and methods
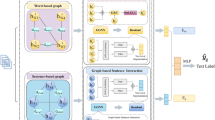
To address the challenges highlighted in the Related Work section, we developed an innovative ML-MC classification approach using propaganda datasets. We proposed a Hierarchical Graph-based Integration Network (H-GIN) for detecting propaganda in text within a specified domain using multilabel classification. H-GIN utilizes bi-layer graph structures with inter- and intra-channel connections, and incorporates techniques such as RDEP and ADMF18,21. This approach employed suitable labels at two distinct classification levels. First, RDEP procedures enhance information exchange between distant nodes. Second, the ADMF integrates Three Channels (sequence, semantic, and syntactic), enabling effective propaganda detection by propagating related and unrelated information from news representations into a classifier. We validated our method on existing datasets, such as ProText, Qprop, and PTC, ensuring its applicability and accessibility to the public. Additionally, our approach incorporates both supervised and unsupervised machine learning techniques, enhancing predictive accuracy and enabling valuable insights for decision-making23,24. In the following subsections, we provide a comprehensive overview of the proposed method, which is detailed in Fig. 2.

Propaganda Detection Pipeline with Embedding, Softmax, and Final Classifier Layer.
Preliminaries
A graph G = (V, E) is defined by a set of vertices V and edges E. Each node vi represents a single element within the graph V, and an edge ei,j = (vi, vj) E signifies a connection between nodes vi and vj. Adjacency matrix A of graph G, where Rn×n encodes the relationships between nodes. Specifically, Ai,j = 1 if edge ei,j E exists; otherwise, Ai,j = 0. Matrix A successfully captured the structural connectivity of the graph. Nodes V and edges E in graph G are represented by the matrices X and E, respectively. Here, X Rn×m contains m-dimensional vectors xi Rm, representing the node attributes. Similarly, ERn×c contains c-dimensional vectors ei,j, Rc representing edge attributes, which have often been reduced to a scalar c = 1 in recent studies for simplicity. Matrix A also serves as the edge feature-weighted adjacency matrix, integrating node and edge representations X and E to capture both structural and attribute-based information within graph G. To construct three unrelated graphs (UGseq, UGsem,UGsyn), we used ADMF to integrate Three Channels while updating graph representations with RDEP (yielding GHseq, GHsem,GHsyn). Thus, to enhance the dependency information between graphs with ADMF (yielding GHs′eq, GHs′em,GHs′yn), and utilize these representations for classification53.
Data pre-processing and coding analysis for building graph
Data-Pre-processing: In the current study, the dataset was pre-processed and the raw text instances were cleaned by removing numbers, non-English letters, punctuation, and special characters (#, $, %, @, &). The pre-processing steps included tokenization using space as the delimiter, removal of stop-words identified from a prepared list, and stemming using a Snowball stemmer18,21. The Snowball stemmer is a text-processing language that supports various languages, including Arabic. Specifically, the following steps were involved in the data pre-processing.
-
Tokenization: Tokenization, also known as text segmentation, involves splitting a text into tokens using a specified delimiter such as commas, white space, periods, and so on. The purpose of tokenization is to divide text into distinct features or units called tokens.
-
Stop-word removal: Stop-words were removed which involves a process that focuses on eliminating insignificant words from the text. Stop-words are commonly occurring words in the text that do not provide useful information and can impact classification performance. Examples of stop-words include prepositions, conjunctions, pronouns, and other similar words.
-
Stemming: Stemming was performed to reduce the derived features to their root or stem forms. This transformation of semantically similar features helps to reduce the feature space, minimize morphological variations in words, and enhance the classification performance of the model.
Analysis for Building Graphs: To train our propaganda detection model, it was critical to identify various propaganda techniques present on online social media platforms. Previous studies have explored several forms of detection and text classification, including fake news54, rumors55, and hate speech56. These studies differentiated between propaganda, fake news, and rumors, categorizing them into distinct types. For an overview of prior research on the classification of propaganda, fake news, and rumors, please refer to54,57.
In qualitative data analysis, coding analysis is a vital method for organizing and interpreting texts. The collaborative coding process, as outlined, involves six progressive steps: (1) preliminary scrutiny and planning, (2) open and axial coding, (3) development of a preliminary codebook,
(4) pilot testing of the codebook, (5) final coding procedures, and (6) reviewing the codebook and deriving themes.
This study followed these steps in the labeling process. Using a random sampling algorithm, 1000 records were chosen from the complete dataset for coding analysis. During the initial stage of the coding analysis, the dataset was thoroughly examined, compared, conceptualized, and categorized. The coding scheme for classifying misinformation, fake news, and propaganda on online platforms was adapted from previous studies that categorized fake news and rumors.
Moreover, in constructing graphs to represent text documents, we define a graph as G = (V,E), where V represents the set of nodes, and E represents the set of edges. Feature matrix X contains all n nodes with m dimensions, where each row xi signifies a vector for node i. Matrix D can be calculated using matrix A, where Di = ∑ jA(i,j). Using the sentence “Trump—is that blue-collar wages have begun to rocket” as an example, we illustrate the feature extraction and graph-construction process. Three channels of graphs were proposed to construct three unrelated graphs: the sequence graph UGseq, semantic graph UGsem, and syntactic graph UGsyn. Each word in the corpus is mapped to a node, and the edge weights are determined syntactic, semantic, and sequential, as shown in Fig. 3.

Coding analysis process, building graph, and feature extraction.
Multichannel 3S feature graphs representation
This section describes the procedure for building cohesive graphs that serve as visual representations of the written materials. Our main objective was to mine three crucial features for creating these graphs. These features are obtained from different elements, namely syntactic dependency, semantic information, and the local sequential context.
Syntactic dependency features
First, the Stanford NLP parser was employed to extract undirected relations between each word pair in the input texts of the corpus. Take, for instance, the sentence “Trump—is that blue-collar wages have begun to rocket” where the extraction results are shown in Fig. 4. Subsequently, the occurrence of syntactic basic and enhanced dependencies among word sets diagonally and the data are tallied. This process involves developing a weight edge (WE) across nodes in the syntactic graph (Gsyn), enabling a realistic evaluation of the degree of dependence, as follows:
where Wsyn (i, j) is the weighted value based on the syntactic feature between nodes i and j, N(i,j) denotes the specific syntactic feature value, Min(Syn) indicates the minimum observed value of the syntactic feature across all relevant nodes, and Max(Syn) denotes the maximum observed value of the syntactic feature across all relevant nodes.

Syntactic dependency features results for given instance sample.
Semantic information features
To improve the comprehension of word relationships, we employed semantic information obtained from cosine similarity computations19,20. Instead of using traditional methods that struggle to determine the meanings of multiple-word phrases, we utilized BERT to collect detailed contextual information and long-term connections. We leveraged BERT’s self-attention tool to create new, precise representations of vectors19. In addition, we simultaneously controlled the level of the semantic characteristics to maintain a low density in the semantic graph Gsem vectors, as shown in Table 1.
Local sequential context features
To demonstrate sequential attributes, we used the concept of local co-occurrence among words. First, we set up a fixed-size window w that offers slides over every piece of text in the data to collect the co-occurrence information. The weights that link nodes consisting of two distinct phrases are computed using point-wise information exchange, which is calculated for each pair of words using the following formula:
Here, PMI represents the pointwise mutual information between words wi and wj; P(wi, wj) denotes the probability of both words occurring together; and P(wi) and P(wj) are the probabilities of each word occurring individually. A logarithmic function is applied to normalize the values.
Multiclass multilabel inter-graph for propaganda detection
Motivated by the Transformer58 prototype, we designed a Multiclass Multilabel Attention Interaction (MMAI) module that can effectively learn the interaction between textual modalities by multichannel. Inter-graph Joint graphs are used to realize homogeneous and heterogeneous information interaction and involve exchanging data between diverse graphs to bolster their insights19,20. To address this objective, an ADMF method is introduced. The overarching architecture depicted in Fig. 5 encompasses the construction of three unrelated 3S channels: sequential, syntactic, and semantic, aimed at encapsulating distinct text properties. Subsequently, enhancement algorithms within each channel were proposed to facilitate the amalgamation of information across various graphs.

Attention-driven multichannel feature fusing framework.
For instance, the unrelated sequence graph UGseq enhanced multichannel entails three primary layers:
-
1.
Layer 1: Initial assignment of different weights based on the significance of syntactic and semantic channel representations within the sequence. In the initial representation, the sequential channel is linked using new relation forms, denoted as ∈ {Usyn,Usem}. Subsequently, a feed-forward network (FFN) comprising a sigmoid activation function is used to calculate the relevant results ∈ {Usyn,Usem}.
-
2.
Layer 2: Implement a simple node-wise attention method to combine syntactic and semantic channel concepts into a single improved vector. Vector O is improved by combining the weighted norms of the syntactic and semantic inter-graph joint information representations.
-
3.
Layer 3: entails revising the sequential representation of word relationships via communication. This process is integrated into an upgraded matrix to constantly use the syntactic and semantic channels of information. The ultimate improved sequential depiction, denoted as e′, is computed using the following interaction formulas:
where e represents the original sequential representation, M denotes the enhanced matrix incorporating additional information, and f denotes the function for message passing by incorporating the enhanced matrix. Word links are relaxed to comprehend in both directions because of the LSTM tri-unit structure. The input, output, and forget states are calculated as follows: Word links are relaxed to comprehend in both directions because of the LSTM tri-unit structure. The input, output, and forget states are calculated, as:
where xt is the input, ig is the input state, og is the output state, and ht is the hidden state, which are connected to the context ({C}_{t}). The input state ig that specifies input, ({beta }_{i}) and ({omega }_{i}) specify the biases and weights for the input state. Whereas the output state og that indicates output, ({omega }_{o}), and ({beta }_{o}) specify the biases and weights for output. The forget state indicates, ({f}_{g}) forget state, where ({omega }_{f}) and ({beta }_{f}) Indicate the weights and biases for the forget state.
Multiclass intragraph information propagation
In this section, we present three crucial elements for the distribution of information within a graph, such as Undirected GCN, RDEP, and global Integrate Layer. All of these elements enable the flow of data across nodes in the structure of a graph.
Undirected graph convolutional network
An undirected GCN is a type of neural network designed to operate on graphs where edges have no inherent directionality, enabling information propagation and feature learning across nodes in the graph structure20. Following the construction of the text graph, it undergoes processing through a two-layer GCN. To refine the essential graph obtained from the previous module and filter out minor noise while preserving strong connectivity relationships, we introduce an adaptive threshold shrinkage function, denoted as ρ( ), which effectively refines the learned adjacency hidden representation matrix H. This function is defined as follows:
where w1, w2, and θi = θ1, θ2,…,θn are learnable parameters, and ReLU is the activation function. The gap between θ1 and θ2 is set as ϵ = 0.05. To maintain this constraint throughout the training process, we utilize a learnable variable θ and apply a Sigmoid activation function to produce θ1 and θ2. The specifics are outlined below:
where ε is the signifies a predefined parameter that quantifies the distinction between θ1 and θ2. Equation (8) introduces the Learnable Piecewise ReLU function, which is compared with ReLU and Soft Thresholding. The subsequent definition outlines the updated formula for a GCN input layer H incorporating the threshold function20, as:
where Z represents a set of tuples, each consisting of any two samples that are in the shared representation matrix Z, H(l) Input of GCNs in the lth layer, H(0) is equal to Z, A = D-1/2ρ(A,θi).
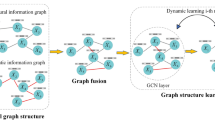
RDEP (residual-driven enhancement and processing)
A two-level hierarchical layer is shown in Fig. 6, where the enhancement and refining processes are carried out separately inside the intra-graph layers. In addition, residual links are added between the interlayers. The following three main techniques are introduced:

Multi-Layer RDEP (Residual-Driven Enhancement and Processing) Framework.
Coarsening Technique: In the following, we will describe a general framework for the textual data coarsening process and provide two instances of this general framework. In the coarsening technique, node sharing can be organized in a concept hierarchy, where the concepts at adjacent layers follow the hypernym relations19,21. We have developed a technique for transforming textual data by moving words in an upward-downward direction. In this process, words first move upwards to their parent nodes, which are more broad or abstract concepts. They then randomly move downwards to the concepts of their children, with an equal chance for each child node, as:
where Ss is Structural similarity, v signifies a graph-based hyper-node, A represents the adjacency matrix, and D is the degree matrix of graph G. Each pair of child nodes (E, F) demonstrates concise similarity are combined into a single hyper-node v. Furthermore, unlabeled nodes like A and D are regarded as distinct hyper-nodes.
The coarsening strategy can be expanded into a multilevel framework by repeating the process described above on the graph associated with the nodes in the coarse set. Let C(⋅) be the coarsening process in original graph G as input, and let G1, G2,…Gh is a sequence of coarse graphs, such that Gl = (Vl,El) is achieved by coarsening on Gl-1 for 1 < l. If C is the set of coarse nodes and F is the set of fine nodes Ac (Coarsen(A)), we can define related subspaces XC and XF of the original space X = Rn. Following input into C(⋅), the coarsened graph Gc (Coarsen(G)) with its matching representation matrix GH′ and dependency matrix A′ is produced. This coarsened graph is expressed as follows:
where M is transfer matrix T, which is defined to handle the grouping relationships during coarsening.
Refining Process: The refining process entails obtaining the graph representation of the existing level and its minor layer coarsened graph by using intrinsic connections of the framework of inter-graph59. The hyper-nodes in the minor layer network are divided into numerous nodes to regain the structure, which allows for efficient transmission of features over a wider field of reception. The refining procedure, denoted as Gr(Coarsen(GHc)), refines the graph representation, utilizing the transfer matrix T obtained during coarsening.
Residual Connection: Introducing a unique hierarchical configuration with a residual connection in inter-layers enhances the depth of the neural network, simplifying training processes for deep neural networks. Following a sequence of roughening and smoothing operations, a residual link is introduced by element-wise inclusion. For instance, when the coarsening layer is set to 1, the graph representation goes through many steps of coarsening and refining before the result is shown as follows:
Residual connections involve adding the original input H to the output F(H) of a layer, aiding in learning residual mappings and mitigating training challenges in deep neural networks. The RDEP is achieved and established on the described structures. The hidden representation H was generated by GCN provided a graph G. The coarsening of graph G in layer 1 of the hierarchical layer produces coarser graphs G′ and G′′, which are then refined to rebuild the structure. Before subsequent refining, a residual connection is applied. This process is repeated, yielding the outcome H′.
Information interactions between distant nodes
The H-GIN model facilitates information interactions between distant nodes through a combination of hierarchical structure and multilayer graph representations19. At each step, nodes aggregate transformed state information from their neighbors and update their states using a GRU and residual connections, ensuring efficient and dynamic information exchange. The key components include RDEP, which refines edge weights and connects nodes across layers, and ADMF, which dynamically adjusts the importance of nodes and edges. These mechanisms enable the H-GIN model to effectively capture long-range dependencies, preserving both global and local node data for accurate propaganda detection46. A directed graph features edges with specific directions, indicating the flow from one node to another. In contrast, an undirected graph has edges without designated directions, allowing bidirectional interaction between nodes. As shown in Fig. 6, the directed graph has directed edges, whereas the undirected graph lacks directional edges. Notably, in undirected graphs, each edge can be viewed as comprising two directed edges, facilitating mutual interaction between connected nodes.
Textual graphs 3S integration layers
Each of these three text graphs undergoes separate information using a dual-layer coarsening and refining process, which includes residual connections19. This strategy broadens the modernized series of each node and gathers comprehensive universal context info. Subsequently, a GCN is used together with a softmax classifier to combine node data of unrelated graphs, such as UGseq, UGsyn, and UGsem. To yield 3S unrelated graphs, we utilized ADMF integrates 3S Channels, while modifying graph representations with RDEP (produces GHseq, GHsem, GHsyn). Therefore, to enhance dependency information among graphs with ADMF (produces GHs′eq, GHs′em, GHs′yn), and use such representations for classification53. As a result, new node representations are obtained:
where HL represents the three-channel layer (UGseq, UGsyn, and UGsem) in the input of GCNs. Similarly, the aforementioned technique is iterated for the final classifier to improve the depiction of coding analysis and identification of propaganda. This results in the acquisition of coding analysis, feature representation, and propaganda identification. Furthermore, we use mean pooling to acquire the ultimate representations Hfinal to detect propaganda, in addition to enhancing ML-MC propagation.
Final node classifier layer
In the classification process, the final node representations, denoted as Hfinal, serve as inputs to a softmax layer. This layer functions to forecast the label L of news articles based on the learned representations, as shown in Fig. 7. Through the application of softmax, the model computes the probabilities associated with each possible label, ultimately assigning the most probable label to the given news article19,20,21.

The information pooled into the final classifier in H-GIN model.
This approach enables the classifier to effectively categorize news articles into relevant classes, leveraging the extracted features encoded within the node representations, as:
where b is the bias, and w is the weight of the input, output, and forget state. We aim to reduce the disparity between the true label, and forecast label by employing the cross-entropy function, as:
where L’ is the actual label, and yi is the one-hot vector corresponding to the point between the validity label and the anticipated label.
Hierarchical pooling
Hierarchical pooling methods aim to preserve the structural information of hierarchical graphs by iteratively coarsening the graph into a smaller version19. These methods can be broadly classified into node clustering pooling, node drop pooling, and other pooling techniques based on how they coarsen a graph.
Node drop pooling
This method retains nodes from the original graph by deleting nodes with lower significance scores using a learnable scoring function. It consists of three main modules:
-
1.
Score Generator: Calculates significance scores for each node in the input graph.
-
2.
Node Selector: Selects the top-k nodes with the highest significance scores.
-
3.
Graph Coarsening: Creates a new graph from the selected nodes by learning a new feature matrix and an adjacency matrix.
These hierarchical pooling methods21, while employing flat pooling methods (readout) to obtain the graph-level representation of the coarsened graph, offer various ways to coarsen and process graphs, each with unique advantages in handling graph structure and data reduction.
Experiments and results analysis
In this section, we outline the experimental setup, datasets utilized for evaluating the framework, and performance metrics employed.
Experiment configuration
Dataset
In our evaluation, we employed well-known propaganda datasets QProp, PTC, and ProText, which have been annotated at the fragment and document levels2. QProp is a publicly available annotated corpus offered by the Proppy system60 at the document-level. It consisted of 51,000 instances sourced from more than 100 news sites. Article labels are assigned based on assessments made by the Media Bias/Fact Check (MBFC) group by propaganda and the level of trustworthiness samples. The dataset comprised 37,000 news articles classified as non-propaganda and 14,000 news items classified as propaganda. Data augmentation is used to counteract the imbalance in propaganda pieces. The preparation includes eliminating terms with low frequency and retaining only the first 50 words of each text to develop the corpus with our model. The PTC dataset used for SemEval-2020 Task 11: Detection of propaganda techniques in news items consisted of 451 news items and 20,110 sentences. Each phrase is categorized as propaganda or non-propaganda2. At the fragment annotation level, it includes particular pieces within news stories that include propaganda methods. Preprocessing was performed on the dataset to remove text that was categorized as propaganda and separate it from text that was not propaganda. This approach yielded 9,991 non-propaganda and 5,058 propaganda news instances.
Nevertheless, ProText collection is motivated by SemEval (2019–20), Qprop60, and PTC2, and keeps these data as standards for annotating ProText. However, these datasets are only available for general themes/topics, making them less useful for classification purposes. Statistically, ProText has 12,470 instances, of which 7,345 are top instances on Facebook and 4,503 are the most popular tweets for developing the training, development, and testing data, with a split ratio of 0.7:0.1:0.2, as shown in Table 2. Sampling was performed by categorizing instances based on six propaganda techniques and themes.
Experimental Configuration: This section provides a comprehensive overview of the experiment, including the dataset, experimental environment setup, and results. The experimental setup involved training and testing models on Nvidia GTX 1070Ti GPUs equipped with 16 GB of DDR3 RAM running on a 64-bit Windows 10 operating system. The study utilized an ensemble model implemented using the Hugging-Face library. The coding environment was configured in Python 3.60, utilizing the PyTorch framework, and a cross-entropy improvement technique was employed after data preprocessing.
Hyper-parameters tuning
In our experiments, the model was augmented with hidden dimensions of 768 × 100 and pre-trained using RoBERTa. To mitigate overfitting, a dropout value of 0.5 was chosen, following the approach outlined in Probst and Wright61. Additionally, the Hyperband algorithm described by Li et al.62 was employed. This allowed us to compare its performance with popular Bayesian optimization methods for hyperparameter optimization in ML-MC problems. The ML-MC model, configured with 10 epochs and batch sizes of 16, was tuned using an Adam optimizer. The learning rate was set within the range of 2 − 5 × 10−3 (with a maximum of 2 and a minimum of 5), and weight decay varied from 0.1 to 0.001 for other hyper-parameters.
Performance metrics
The effectiveness of the proposed models was evaluated using various established criteria including precision (P), recall (R), accuracy (Acc), and weighted F1-score. These metrics, based on standard terminology, involve true negatives (Tn), false negatives (Fn), true positives (Tp), and false positives (Fp), contributing to precision and recall calculations. These metrics are widely used to assess a model’s performance. Notably, the weighted F1-score, which represents a weighted average of the F1-scores for individual classes, was calculated, taking the class size into account.
Baselines
We utilized various competitive models as baselines to evaluate the performance of state-of-the-art (SOTA) models on our benchmark dataset. Each experiment was repeated five times, and the average score was used for the analysis to ensure a comprehensive comparison. To maintain fairness and robustness, identical parameters were applied across the experiments on the same ProText dataset and encoder. The evaluated approaches included traditional neural networks, pre-trained language models, and graph-based neural networks.
Hybrid neural network and traditional approach
To comprehensively evaluate our proposed method for semi-supervised short-text classification, we compared it with the following nine state-of-the-art methods: Text Convolutional Neural Network (TCNN)14 and Long Short-Term Memory (LSTM)63:
-
LSTM63 uses the last hidden state as the representation of the whole text. We also experimented with the model and with without pretrained word embeddings.
-
TCNN14 explored CNN-rand, which uses randomly initialized word embeddings, and CNN-non-static, which uses pre-trained word embeddings.
Self attention-based transformer architectures
A threshold of 0.3 was set, leading to the rejection of outputs below this value for RoBERTa (Robustly Optimized BERT Pretraining Approach)64, MT-DNN (Multi task Deep. Neural Network)65, XLNET66, and ALBERT (A Lite BERT) networks67. The cross-entropy loss function was utilized to train these models.
-
RoBERTa64 is pretrained on a large corpus and can generate contextual embeddings when applied to specific tasks. Here, we use BERT-base and RoBERTa-base, which are fine-tuned along with the classifier for short texts.
-
BERT8 was pretrained on the unlabeled data for various pretraining tasks. Fine-tuning involved initializing the parameters with pre-trained values, which were then fine-tuned using labeled downstream data.
-
MT-DNN65 improved BERT models, including MT-DNN, and has emerged as a SOTA method.
-
Transformer-XL66 pre-training in XLNET incorporates concepts from Transformer-XL, which is an advanced model.
-
ALBERT67 enhances the BERT training speed by reducing the parameters and memory consumption.
Graph-based neural networks approach
In this section, we use a GCN using positions and edges (PEGCN)68, Heterogeneous Graph Attention Networks (HGAT)29, Graph Incompatible learning For short Text classification (GIFT)69, Text GCN (TGCN)17, and Graph convolution network and Bert Combined with co-Attention (GBCA)70 as a graph-based neural network approach baseline. Graph-based models employ node connections to maintain general graph information and demonstrate clear relationships between text parts.
-
PEGCN68 disregards text positional information in GNNs by utilizing input representations with positional information in the word-embedding section.
-
HGAT29 dual-level attention mechanism can learn the importance of different neighboring nodes and the importance of different node types to the current node.
-
GIFT69 learns better short-text representations and solves the challenges of the existing models.
-
TGCN17 models the text corpus as a graph containing documents and words as nodes and applies GCN for text classification.
-
GBCA70 trains for graph classification on fake news propagation, extracts semantic features with BERT, and then integrates them using co-attention for enhanced detection.
Results analysis
Extensive experiments were conducted to assess the effectiveness of the H-GIN model. Overall, our model outperforms existing methods, showing its higher ability to discern the propaganda objectives of news articles on social media or online social networks. For the experiment, we first selected the ProText dataset; the results are listed in Table 3. The suggested baseline models provide robust performance, with classic neural networks such as LSTM and TCNN showing exceptional results14. The LSTM model achieved an accuracy of 80.6%. By properly capturing the overall semantic structure, it combines the connections between the values at the beginning and end of a series. Nevertheless, it is limited by the dimension of the convolution kernel, which hinders it from acquiring long-term dependencies and running efficiently owing to the presence of additional parameters. At the same time, the TCNN obtained an accuracy of 81.3%. Kernels using convolution underlying the main feature can be used to obtain specific parameters.
Thereafter, the PLMs model evaluation scores were lower in the proposed baseline models; however, the RoBERTa model achieved a top-weighted F1 score (0.8011). After performing multiple tests, such as modifying dropout sizes and learning rates, we found that RoBERTa tended to classify the test set as non-propaganda. This indicates that the algorithm can overfit the limited ProText dataset owing to the major impact of PLMs weights. In comparison, our model demonstrated stability and achieved scores only for the best performing models. Notably, despite the unbalanced dataset, our H-GIN model attained the highest F1 score of 83.6%, demonstrating its ability to accurately detect propaganda in textual news.
Graph-based models, notably GBCA, demonstrated strong performance, with a top accuracy of 82.4%. GBCA creates distinct graphs for individual texts, thereby enhancing word co-occurrence relationships. Both GBCA and our model (H-GIN) consider local word co-occurrence when extracting text features. However, H-GIN additionally extracts three channel layers, syntactic, semantic, and semantic features, as evidenced by experimental results confirming their effectiveness. Consequently, we suggest that relying solely on a single-channel layer, such as sequential or semantic information, may not accurately classify propaganda techniques.
In our experiment on the PTC dataset, our model demonstrated superior performance compared with the others in terms of accuracy, recall, and F1 score, as shown in Table 4. LSTM achieved an accuracy of only 77.5%, highlighting its limitations in identifying distant and non-adjacent word relationships because of its emphasis on word locality and sequence. By contrast, PLMs and graph-based models can be used to identify related information over long distances. Compared with the ProText dataset, a large number of these PLM outcomes exhibit inadequate performance, even if they are not overfitted. This result may be linked to the fact that the weights of the pretrained language models are large for an insufficient dataset, such as sentence-level text.
Generally, the graph-based methods PEGCN, GIFT, and GBCA achieved better performance on the PTC dataset, surpassing 80%, indicating that graph-based methods can make better use of limited labeled data through information propagation. GIFT achieves a recall of 85.1%, surpassing our model, but it achieves lower precision values and F1-score. The imbalance in the dataset poses challenges for the model, affecting its ability to learn from positive samples and leading to skewed learning outcomes, potentially resulting in lower precision values and F1-score. GBCA also achieved a higher performance by utilizing BERT PLMs, extracting features from the textual content of fake news, and offering richer evidence and clues. HGAT achieves lower accuracy among these graph-based models, suggesting that its dual-level attention mechanism, which includes node- and type-level attention, is insufficient for capturing the characteristics of propaganda techniques solely through global graph information. Moreover, the output distinguishing features may be overfitted by adding too many convolutional layers, which reduces the sensitivity of the model to fine-grained data details. In contrast to HGAT, which focuses on capturing context information within a graph, we introduced ADMF to enhance propaganda detection by incorporating related and unrelated information propagation, and pooling news representations into a classifier.
To assess the suitability of H-GIN at the span level for the dataset, we performed an experiment with the Qprop dataset, and its performance is outlined in Table 4. These PLMs models outperformed the baseline models and indicated no signs of overfitting on the Qprop dataset. Notably, PLMs demonstrated outstanding performance on the Qprop dataset, capturing comprehensive semantic information in long texts. Lower F1 scores were obtained by BERT, even though it achieved a precision value of 88.5%, indicating difficulties in learning positive samples. Our model outperformed ALBERT, the top-performing PMLs baseline model, by approximately 5%. The receptive field on text graphs is improved by our proposed RDEP, which is more efficient than ALBERT, which incorporates deep LSTMs to gather extensive data. Nevertheless, the performance of graph-based neural networks on the Qprop dataset was lower, with PEGCN exhibiting the worst accuracy among all baseline models, with only 49.7% accuracy. Unlike the other datasets, HGAT exhibited robust results in this study, suggesting its appropriateness for fragment-level datasets. Both HGAT and our model use coarsening processes to extend the sensitive field, thereby improving the graphic representation of the resulting model. Our model surpasses PLMs and traditional NN by enhancing the network depth via the new RDEP, which effectively preserves global and local node information.
Ablation study
We employed ablation studies to systematically analyze the impact of individual components or features of a model by removing or altering them, helping to understand their contribution to the overall performance.
Analysis of three-channel feature graphs representation
This section outlines the method for constructing cohesive text graphs, which serve as textual representations of the written materials. Our primary aim is to extract three essential features to construct these graphs: syntactic dependency, semantic information, and local sequential context obtained from various elements. We also performed an ablation study with and without three channel features, as shown in Table 5. The performance is depicted in Fig. 8, where we evaluate the efficiency of these features in building unrelated graphs.

Accuracy for three channel feature information across all three datasets With H-GIN.
The absence of syntactic feature information led to decreased accuracy across all three datasets, with H-GIN particularly affected. However, the overall performance decrease was relatively small, emphasizing the importance of syntactic features in contextual information capture. Meanwhile, the absence of semantic features significantly decreases the model accuracy across all datasets, especially in PTC and Qprop, where word structure is prevalent. Addressing this issue is crucial, and our method effectively mitigates it by enhancing the semantic feature accuracy. Sequential feature absence notably impacts accuracy, especially in the ProText dataset, owing to its small size and limited information. Conversely, larger datasets, such as PTC and Qprop, compensate through semantic and syntactic features, highlighting the importance of sequential features in capturing global contextual information.
In summary, G-HFIN outperformed each of the distinct modifications. The accuracy of these variations is reduced when only a few features are considered, demonstrating the coordinating nature of the three diverse graphs generated by sequential, syntactic, and semantic information. Together, these components have a major function in adopting propaganda strategies by providing abundant information. Furthermore, unique features have diverse effects on the collection of text-based data. Specifically, the lack of sequential characteristics leads to the most significant loss in accuracy in the PTC dataset, underscoring the importance of obtaining relationships between words that appear close to each other in brief texts. Nevertheless, the lack of syntactic or semantic features resulted in a significant decrease in accuracy throughout the three datasets, highlighting their importance in detecting word dependencies across vast gaps and interpreting multiple meanings of words.
Analysis of multiclass inter-intra graph representation
In order to promote and confirm the efficacy of multiclass Intra-Inter graph Information Propagation and Enhancement, we performed ablation tests on three datasets, specifically examining two key aspects: RDEP and ADMF. Within this part, we have created two different versions of H-GIN: H-GIN (RDEP) and H-GIN (ADMF). We then proceeded to analyze and evaluate their respective outperforms H-GIN (RDEP) in terms of performance, as seen in Fig. 9a. In the context of the residual-driven enhancement and refinement technique, H-GIN outperforms H-GIN (RDEP) in terms of performance, as seen in Fig. 9b. The low efficiency of H-GIN (RDEP) may be ascribed to its constraint of transferring information primarily across distinct graphs. The lack of intra-graph information propagation restricts the movement of textual information among nodes, leading to a deficiency in global information, as shown in Fig. 9c. The effect is much more noticeable in Qprop than in ProText and PTC, indicating that RDEP is better suited for broader corpora. However, small corpora, such as ProText and PTC, may still successfully gather worldwide data by using a single layer of GCN because of their lower node sizes, as shown in Fig. 9d. However, for larger corpora such as Qprop, a single layer of GCN is lacking for retrieving information from faraway nodes with no intra-graph exchange of data. Moreover, excessive GCN layers result in excessively refined features.

Results performance of inter-intra graph information propagation and enhancement comparison.
The proposed H-GIN(-ADMF) model aims to integrate features from distinct graphs by employing achievable weights as part of the attention-driven multichannel feature fusion approach. However, the precision of H-GIN(-ADMF) is inferior to that of H-GIN. Although the module effectively combines characteristics utilizing adjustable weights, it does not have a specific method for improving each feature before the fusion process. Consequently, it is difficult to enhance node representations to accurately identify intricate propaganda strategies, highlighting the efficiency of the ADMF. As a result of the analyses of the above ablation experiment, it can be concluded that all the main parts of H-GIN are effective, and it is essential for propaganda detection and classification using English datasets.
Theoretical and practical implications
This study makes critical theoretical contributions enriched by the diffusion of innovations theory, providing deeper insights into propaganda detection within the broader context of the Information Systems (IS) domain.
Theoretically, this study advances the understanding of multimodal data integration for text-classification tasks. By introducing a novel graph-based network, H-GIN19,21,53, which constructs bi-layer graphs with inter- and intra-channel integration, this study demonstrates the potential of combining syntactic, semantic, and sequential information for more accurate text classification. This multidimensional approach not only enhances the detection capabilities for propaganda but also opens new avenues for research in other areas where multimodal data integration could be beneficial, such as sentiment analysis and opinion mining. This multiclass graph model bridges the prior separation between ML and MC tasks16,19,38 and delves into the interplay between outcome expectations and media bias/fact-checking. Additionally, the incorporation of advanced techniques, such as RDEP and ADMF, within the graph construction process underscores the importance of residual learning and attention mechanisms in improving model performance and interpretability.
Practically, this study has significant implications for the development of robust and reliable tools for detecting misinformation on social media platforms. As online misinformation continues to be a pervasive issue, the ability to accurately identify and classify various forms of propaganda can mitigate its spread and impact. The methodology proposed in this study can be adapted and applied to real-world applications such as monitoring social media for harmful content, aiding fact-checking organizations, and supporting governmental and non-governmental efforts in countering misinformation. Furthermore, this study’s use of a comprehensive coding analysis process and the development of a cohesive graph-based representation of text documents provide a framework that can be utilized by developers and researchers to create more sophisticated NLP models.
Finally, this research has implications for educational and training programs that focus on digital literacy and critical thinking. By understanding the underlying mechanisms and features that characterize propaganda, educators can develop more effective curricula to teach individuals how to critically evaluate the information they encounter online. The findings of this study can inform the creation of educational tools and resources that help individuals recognize and respond to misinformation, thereby fostering a more informed and discerning public. Overall, the theoretical advancements and practical applications of this study contribute to broader efforts to combat misinformation and promote a healthier information ecosystem.
Conclusion, Limitations, and Future Directions
This study introduces a Hierarchical Graph-based Integration Network (H-GIN) that is specifically intended to identify propaganda in text within a certain topic using multilabel categorization. The H-GIN is used to construct a three-channel graph, consisting of the RDEP, ADMF, and final classifier. RDEP procedures specifically enable the exchange of information between remote nodes, whereas ADMF standardizes Three Channels, namely sequence, semantic, and syntactic information. This standardization allows for the effective detection of propaganda by analyzing the spread of related and unrelated information, and then consolidating news representations into a classifier.
This study has some limitations. First, the availability of labeled propaganda datasets is a significant limitation in propaganda detection. Acquiring extensive and varied datasets containing labeled instances of propaganda poses a challenge, typically necessitating manual annotation by experts. To enhance propaganda detection, automated ML models should be built to process a large volume of training data for annotation, marking a promising direction for further investigation. Second, propaganda techniques differ across domains, languages, and cultures, which can affect the generalizability of findings to other contexts. To address this, expanding propaganda detection research in various languages is essential to tackle the challenges posed by cross-lingual propaganda. Developing models capable of detecting propaganda in multiple languages is crucial for countering campaigns aimed at diverse linguistic communities. Future research should focus on mitigating biases, ensuring fairness, and establishing guidelines for responsible deployment of propaganda detection systems. Third, DL models, such as ML-MC, can be complex and challenging to interpret. Discerning the precise factors or linguistic cues that drive propaganda detection can be challenging, thus hindering insights into the underlying mechanisms. Future research avenues may explore incremental or lifelong learning methods for training the H-GIN model. Enabling continuous adaptation to new propaganda instances would help tackle evolving techniques and ensure a more robust detection system. For more deep learning tasks, it is recommended to review several studies, such as query response71, neural network algorithms72,73,74, and recent advancements in model architectures, such as transformers and GANs. This can provide insights into optimizing the performance and understanding state-of-the-art techniques.
Data availability
Data is available upon request from the corresponding author.
References
-
Wang, X., Wang, X., Min, G., Hao, F. & Chen, C. L. P. An efficient feedback control mechanism for positive/negative information spread in online social networks. IEEE Trans. Cybern.52, 87–100 (2022).
-
Da San Martino, G., Barrón-Cedeño, A. & Nakov, P. Findings of the NLP4IF-2019 Shared Task on Fine-Grained Propaganda Detection. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda 162–170 (Association for Computational Linguistics, Hong Kong, China, 2019). https://doi.org/10.18653/v1/D19-5024.
-
Gupta, P., Saxena, K., Yaseen, U., Runkler, T. & Schütze, H. Neural Architectures for Fine-Grained Propaganda Detection in News. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda 92–97 (Association for Computational Linguistics, Hong Kong, China, 2019). https://doi.org/10.18653/v1/D19-5012.
-
Jowett, G. S. & O’donnell, V. Propaganda & Persuasion (Sage publications, Thousand Oaks, 2018).
-
Da San Martino, G., Yu, S., Barrón-Cedeno, A., Petrov, R. & Nakov, P. Fine-grained analysis of propaganda in news article. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) 5636–5646 (2019).
-
Allcott, H. & Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect.31, 211–236 (2017).
-
Huang, H., Sun, Y. & Chu, Q. Can we-media information disclosure drive listed companies’ innovation?—From the perspective of financing constraints. China Finance Rev. Int.12, 477–495 (2022).
-
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (eds. Burstein, J., Doran, C. & Solorio, T.) 4171–4186 (Association for Computational Linguistics, Minneapolis, Minnesota, 2019). https://doi.org/10.18653/v1/N19-1423.
-
Da San Martino, G. et al. A survey on computational propaganda detection. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence 4826–4832 (Yokohama, Yokohama, Japan, 2021).
-
Li, W. et al. Span identification and technique classification of propaganda in news articles. Complex & Intelligent Systems 1–10 (2021).
-
Feng, Z. et al. Alpha at semeval-2021 task 6: Transformer based propaganda classification. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021) 99–104 (2021).
-
Zhang, Y. et al. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks. in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (eds. Jurafsky, D., Chai, J., Schluter, N. & Tetreault, J.) 334–339 (Association for Computational Linguistics, Online, 2020). https://doi.org/10.18653/v1/2020.acl-main.31.
-
Wu, Z. et al. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst.32, 4–24 (2020).
-
Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) 1746–1751 (Association for Computational Linguistics, Doha, Qatar, 2014). https://doi.org/10.3115/v1/D14-1181.
-
Li, J. & Xiao, L. syrapropa at SemEval-2020 Task 11: BERT-based Models Design for Propagandistic Technique and Span Detection. In Proceedings of the Fourteenth Workshop on Semantic Evaluation 1808–1816 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.237.
-
Yoosuf, S. & Yang, Y. Fine-grained propaganda detection with fine-tuned BERT. In Proceedings of the second workshop on natural language processing for internet freedom: censorship, disinformation, and propaganda 87–91 (2019).
-
Liu, T., Hu, Y., Gao, J., Sun, Y. & Yin, B. Hierarchical Multi-granularity Interaction Graph Convolutional Network for Long Document Classification. IEEE/ACM Transactions on Audio, Speech, and Language Processing (2024).
-
Du, J., Jin, J., Zhuang, J. & Zhang, C. Hierarchical graph contrastive learning of local and global presentation for multimodal sentiment analysis. Sci. Rep.14, 5335 (2024).
-
Liu, T., Hu, Y., Gao, J., Sun, Y. & Yin, B. Hierarchical Multi-Granularity Interaction Graph Convolutional Network for Long Document Classification. IEEE/ACM Transactions on Audio, Speech, and Language Processing (2024).
-
Du, J., Jin, J., Zhuang, J. & Zhang, C. Hierarchical graph contrastive learning of local and global presentation for multimodal sentiment analysis. Sci. Rep.14, 5335 (2024).
-
Qian, S., Wang, J., Hu, J., Fang, Q. & Xu, C. Hierarchical Multi-modal Contextual Attention Network for Fake News Detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval 153–162 (ACM, Virtual Event Canada, 2021). https://doi.org/10.1145/3404835.3462871.
-
Ren, Q., Zhou, B., Yan, D. & Guo, W. Fake News Classification Using Tensor Decomposition and Graph Convolutional Network. IEEE Transactions on Computational Social Systems (2023).
-
Paul, R. & Elder, L. How to detect media bias and propaganda. Dillon Beach, CA: Foundation for Critical Thinking (2006).
-
Rodrigo-Ginés, F.-J., Carrillo-de-Albornoz, J. & Plaza, L. A systematic review on media bias detection: What is media bias, how it is expressed, and how to detect it. Expert Syst. Appl.237, 121641 (2023).
-
Da San Martino, G., Barrón-Cedeño, A., Wachsmuth, H., Petrov, R. & Nakov, P. SemEval-2020 Task 11: Detection of propaganda techniques in news articles. In Proceedings of the Fourteenth Workshop on Semantic Evaluation 1377–1414 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.186.
-
Alam, F., Mubarak, H., Zaghouani, W., Da San Martino, G. & Nakov, P. Overview of the WANLP 2022 Shared Task on Propaganda Detection in Arabic. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP) (eds. Bouamor, H. et al.) 108–118 (Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), 2022). https://doi.org/10.18653/v1/2022.wanlp-1.11.
-
Mustafa, H. T., Shamsolmoali, P. & Lee, I. H. TGF: Multiscale transformer graph attention network for multi-sensor image fusion. Expert Syst. Appl.238, 121789 (2024).
-
Brynte, L., Iglesias, J. P., Olsson, C. & Kahl, F. Learning structure-from-motion with graph attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 4808–4817 (2024).
-
Linmei, H., Yang, T., Shi, C., Ji, H. & Li, X. Heterogeneous graph attention networks for semi-supervised short text classification. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) 4821–4830 (2019).
-
Zeng, Y., Li, Z., Tang, Z., Chen, Z. & Ma, H. Heterogeneous graph convolution based on in-domain self-supervision for multimodal sentiment analysis. Expert Syst. Appl.213, 119240 (2023).
-
Wang, F., Zhu, X., Cheng, X., Zhang, Y. & Li, Y. Mmkdgat: Multi-modal knowledge graph-aware deep graph attention network for remote sensing image recommendation. Expert Syst. Appl.235, 121278 (2024).
-
Khademi, M. Multimodal neural graph memory networks for visual question answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 7177–7188 (2020).
-
Huang, L., Ma, D., Li, S., Zhang, X. & Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (eds. Inui, K., Jiang, J., Ng, V. & Wan, X.) 3444–3450 (Association for Computational Linguistics, Hong Kong, China, 2019). https://doi.org/10.18653/v1/D19-1345.
-
Li, Q., Han, Z. & Wu, X.-M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the AAAI conference on artificial intelligence vol. 32 (2018).
-
Hussain, S. et al. Vulnerability detection in Java source code using a quantum convolutional neural network with self-attentive pooling, deep sequence, and graph-based hybrid feature extraction. Sci. Rep.14, 7406 (2024).
-
Vosoughi, S., Roy, D. & Aral, S. The spread of true and false news online. Science359, 1146–1151 (2018).
-
Tall’on-Ballesteros, A. Emotion-enhanced multi-modal persuasive techniques detection using split features. In Fuzzy Systems and Data Mining VIII: Proceedings of FSDM 2022358, 172 (2022).
-
Chen, P., Zhao, L., Piao, Y., Ding, H. & Cui, X. Multimodal visual-textual object graph attention network for propaganda detection in memes. Multimed Tools Appl83, 36629–36644 (2023).
-
Dimitrov, D. et al. Detecting Propaganda Techniques in Memes. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (eds. Zong, C., Xia, F., Li, W. & Navigli, R.) 6603–6617 (Association for Computational Linguistics, Online, 2021). https://doi.org/10.18653/v1/2021.acl-long.516.
-
Zhou, Y., Chen, Z. & Yang, H. Multimodal learning for hateful memes detection. In 2021 IEEE International conference on multimedia & expo workshops (ICMEW) 1–6 (IEEE, 2021).
-
Ahmad, P. N., Liu, Y., Ali, G., Wani, M. A. & ElAffendi, M. Robust benchmark for propagandist text detection and mining high-quality data. Mathematics11, 2668 (2023).
-
Ahmad, P. N., Yuanchao, L., Aurangzeb, K. & Anwar, M. S. Semantic web-based propaganda text detection from social media using meta-learning. Service Oriented Computing and Applications 1–15 (2024).
-
Abrams, E. M. et al. The COVID-19 pandemic: Adverse effects on the social determinants of health in children and families. Ann. Allergy Asthma Immunol.128, 19–25 (2022).
-
Dewantara, D. S., Budi, I. & Ibrohim, M. O. 3218IR at SemEval-2020 Task 11: Conv1D and Word Embedding in Propaganda Span Identification at News Articles. In Proceedings of the Fourteenth Workshop on Semantic Evaluation 1716–1721 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.225.
-
Volkova, S., Shaffer, K., Jang, J. Y. & Hodas, N. Separating facts from fiction: Linguistic models to classify suspicious and trusted news posts on twitter. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) 647–653 (2017).
-
Li, J. & Xiao, L. syrapropa at SemEval-2020 Task 11: BERT-based Models Design for Propagandistic Technique and Span Detection. In Proceedings of the Fourteenth Workshop on Semantic Evaluation (eds. Herbelot, A. et al.) 1808–1816 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.237.
-
Paraschiv, A., Cercel, D.-C. & Dascalu, M. UPB at SemEval-2020 Task 11: Propaganda Detection with Domain-Specific Trained BERT. In Proceedings of the Fourteenth Workshop on Semantic Evaluation 1853–1857 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.244.
-
Chernyavskiy, A., Ilvovsky, D. & Nakov, P. Aschern at SemEval-2020 Task 11: It Takes Three to Tango: RoBERTa, CRF, and Transfer Learning. In Proceedings of the Fourteenth Workshop on Semantic Evaluation 1462–1468 (International Committee for Computational Linguistics, Barcelona (online), 2020). https://doi.org/10.18653/v1/2020.semeval-1.191.
-
Ahmad, P. N., Liu, Y., Ullah, I. & Shabaz, M. Enhancing coherence and diversity in multi-class slogan generation systems. ACM Trans Asian Low-Resour. Lang. Inf. Process.23, 1–24 (2024).
-
Chen, H., Wu, L., Chen, J., Lu, W. & Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inform. Process. Manage.59, 102798 (2022).
-
Hua, Y. Understanding BERT performance in propaganda analysis. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda 135–138 (2019). https://doi.org/10.18653/v1/D19-5019.
-
Thorne, J. & Vlachos, A. Automated Fact Checking: Task Formulations, Methods and Future Directions. In Proceedings of the 27th International Conference on Computational Linguistics 3346–3359 (Association for Computational Linguistics, Santa Fe, New Mexico, USA, 2018).
-
Liu, X. et al. G-HFIN: graph-based hierarchical feature integration network for propaganda detection of we-media news articles. Eng. Appl. Artif. Intell.132, 107922 (2024).
-
Gupta, M., Dennehy, D., Parra, C. M., Mäntymäki, M. & Dwivedi, Y. K. Fake news believability: The effects of political beliefs and espoused cultural values. Inform. Manage.60, 103745 (2023).
-
Guo, F., Zhou, A., Zhang, X., Xu, X. & Liu, X. Fighting rumors to fight COVID-19: Investigating rumor belief and sharing on social media during the pandemic. Comput. Human Behav.139, 107521 (2022).
-
del Valle-Cano, G., Quijano-Sánchez, L., Liberatore, F. & Gómez, J. SocialHaterBERT: A dichotomous approach for automatically detecting hate speech on Twitter through textual analysis and user profiles. Expert Syst. Appl.216, 119446 (2023).
-
del Valle-Cano, G., Quijano-Sánchez, L., Liberatore, F. & Gómez, J. SocialHaterBERT: A dichotomous approach for automatically detecting hate speech on Twitter through textual analysis and user profiles. Expert Syst. Appl.216, 119446 (2023).
-
Ahmad, P. N., Shah, A. M. & Lee, K. Propaganda Detection in Public Covid-19 Discussion on Social Media. 193 (2023).
-
Yao, L., Mao, C. & Luo, Y. Graph convolutional networks for text classification. Proc. AAAI Conf. Artif. Intell.33, 7370–7377 (2019).
-
Barrón-Cedeno, A., Jaradat, I., Da San, M. G. & Nakov, P. Proppy: Organizing the news based on their propagandistic content. Inform. Process. Manage.56, 1849–1864 (2019).
-
Probst, P., Wright, M. N. & Boulesteix, A. Hyperparameters and tuning strategies for random forest. WIREs Data Min. Knowl.9, e1301 (2019).
-
Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A. & Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res.18, 1–52 (2018).
-
Liu, P., Qiu, X. & Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence 2873–2879 (AAAI Press, New York, New York, USA, 2016).
-
Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv preprint.arXiv:1907.11692 (2019).
-
Chi, H. V. T., Anh, D. L., Thanh, N. L. & Dinh, D. English-Vietnamese cross-lingual paraphrase identification Using MT-DNN. Eng. Technol. Appl. Sci. Res.11, 7598–7604 (2021).
-
Yang, Z. et al. XLNet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd International Conference on Neural Information Processing Systems 5753–5763 (Curran Associates Inc., Red Hook, NY, USA, 2019).
-
Lan, Z. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint.arXiv:1909.11942 (2019).
-
Zhang, R., Guo, Z. & Huan, H. Text classification based on PEGCN : Graph convolution classification using location information and edge features. Expert Syst.41, e13511 (2024).
-
Liu, Y., Huang, L., Giunchiglia, F., Feng, X. & Guan, R. Improved graph contrastive learning for short text classification. Proc. AAAI Conf. Artif. Intell.38, 18716–18724 (2024).
-
Zhang, Z. et al. GBCA: Graph convolution network and BERT combined with Co-attention for fake news detection. Pattern Recognit. Lett.180, 26–32 (2024).
-
Rehman, M. Z. U., Raghuvanshi, D. & Kumar, N. KisanQRS: A deep learning-based automated query-response system for agricultural decision-making. Comput. Electron. Agric.213, 108180 (2023).
-
Anwar, N., Ahmad, I., Kiani, A. K., Shoaib, M. & Raja, M. A. Z. Novel intelligent predictive networks for analysis of chaos in stochastic differential SIS epidemic model with vaccination impact. Math. Comput. Simul.219, 251–283 (2024).
-
Anwar, N. et al. Design of intelligent Bayesian supervised predictive networks for nonlinear delay differential systems of avian influenza model. Eur. Phys. J. Plus138, 911 (2023).
-
Anwar, N., Ahmad, I., Kiani, A. K., Shoaib, M. & Raja, M. A. Z. Intelligent solution predictive networks for non-linear tumor-immune delayed model. Comput. Methods Biomech. Biomed. Eng.27, 1091–1118 (2024).
Acknowledgements
This research was support by Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This research was also support by Ningbo China Institute for Supply Chain Innovation, Ningbo, China, and Jiangxi University of Finance and Economics, Nanchang, Jiangxi, China. The authors would also like to thanks Prince Sultan University for their valuable support.
Funding
This research was funded by the Researchers Supporting Project (PNURSP2025R51) at Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
PNA: Conceptualization; Writing-original draf; Writing–Review & Editing, Methodology, Investigation, Data curation, Formal analysis; Visualization, Resources. JG: Conceptualization; Supervision, Writing-original draf; Writing-Review & Editing, Project Administration, Methodology, Formal analysis, Visualization, Resources. NMA: Investigation, Data curation, Resources. QMH: Statistical analysis assistance; Visualization, Formal analysis. SA: Conceptualization; Visualization, Formal analysis, Visualization. ADL: Funding acquisition, Formal analysis. AAA: Formal analysis. All authors have read and agreed to the published version of the manuscript. NOTE: Pir Noman Ahmad (PNA), Jiequn Guo (JG), Nagwa M. AboElenein (NMA), Qazi Mazhar ul haq (QMH), Sadique Ahmad (SA), Abeer D. Algarni (ADL), and Abdelhamied A Ateya (AAA).
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ahmad, P.N., Guo, J., AboElenein, N.M. et al. Hierarchical graph-based integration network for propaganda detection in textual news articles on social media.
Sci Rep 15, 1827 (2025). https://doi.org/10.1038/s41598-024-74126-9
-
Received:
-
Accepted:
-
Published:
-
DOI: https://doi.org/10.1038/s41598-024-74126-9



