



Abstract
The extraction of linguistic markers from social media posts, which are indicative of the onset and course of mental disorders, offers great potential for mental healthcare. In the present study, we extracted over one million posts from the popular social media platform Reddit to analyze speech coherence, which reflects formal thought disorder and is a characteristic feature of schizophrenia and associated psychotic disorders. Natural language processing (NLP) models were used to perform an automated quantification of speech coherence. We could demonstrate that users who are active on forums geared towards disorders with a higher degree of psychotic symptoms tend to show a lower level of coherence. The lowest coherence scores were found in users of forums on dissociative identity disorder, schizophrenia, and bipolar disorder. In contrast, a relatively high level of coherence was detected in users of forums related to obsessive–compulsive disorder, anxiety, and depression. Users of forums on posttraumatic stress disorder, autism, and attention-deficit hyperactivity disorder exhibited medium-level coherence. Our findings provide promising first evidence for the possible utility of NLP-based coherence analyses for the early detection and prevention of psychosis on the basis of posts gathered from publicly available social media data. This opens new avenues for large-scale prevention programs aimed at high-risk populations.
Introduction
Evidence from large epidemiological studies suggests an underrecognition and undertreatment of common mental disorders1. Additionally, access to mental healthcare around the world is severely limited, and individuals suffering from mental illness often fail to receive adequate treatment2. As a consequence, individuals suffering from mental health problems increasingly turn to social media to share their personal experiences, seek information, and receive peer support2,3. Reddit is among the most widely used social media platforms with over 267 million unique active users each week4. On Reddit, users interact with other users by posting or commenting on other people’s posts. By subscribing to forums (“subreddits”) related to mental health such as “r/depression” and “r/anxiety”, users may share their personal experiences with a mental disorder or receive support from peers suffering from the same condition.
Over the past years, analyzing data gathered from Reddit posts has become a powerful tool to gain novel insight into common mental health disorders5,6. Data derived from social media may be used to identify individuals who potentially suffer from mental health problems or to discern the effects of mental disorders on real-life behavior7,8. Therefore, analyzing data from social media data bears great potential to overcome the underrecognition and undertreatment of mental disorders9. The biggest advantage of analyzing social media posts is that they reflect unconstrained behavior under real-life circumstances. This enables the collection of data with a high degree of ecological validity, much unlike data obtained in laboratory conditions10.
Posts from social media forums such as Reddit can be analyzed efficiently by means of natural language processing (NLP)11 to understand processes related to substance abuse12, anxiety and depression5,13,14, suicidality15 or bipolar disorder (BD)16. Social media data has also been utilized in the study of psychosis and schizophrenia (SZ)8,17,18,19,20,21,22,23,24,25,26,27. Posts made by individuals suspected of suffering from psychosis were used to evaluate the nature and impact of COVID-19 on subjective well-being24 or to study their sleep behavior20. Importantly, linguistic features from these posts have been used to predict whether a user is likely or actually suffering from psychosis17,18,19,23,25,26 and whether a symptom relapse is likely to occur18. The ultimate goal of these studies might be the development of systems for the automated and remote prediction, diagnosis, and monitoring of psychosis. Since roughly 5 billion people use social media worldwide28, the analysis of online behavior could allow mental healthcare to reach more people, especially those who have otherwise no access to it.
Disorganized speech is a prevalent characteristic among individuals diagnosed with psychotic disorders such as SZ. This symptom reflects one important domain of formal thought disorder (FTD), which is a key symptom of SZ, and can be derived from the analysis of language29 produced in the context of real-life narratives30. One specific aspect of disorganized speech, termed “speech coherence”, refers to the flow in the meaning in sentences31. Speech coherence can be measured using computational methods32,33. The computational measurement of coherence corresponds mainly to aspects of positive thought disorder, namely tangentiality and derailment of speech31, which reflect a “loosening of associations”34,35. This dimension of speech impairment is characteristic of schizophrenia and other psychotic disorders34 and thus can be used to determine whether psychosis-related symptomatology is present within a certain population.
Multiple studies have tested whether the automated assessment of speech coherence may be used to detect SZ. The results suggest a lower coherence in patients suffering from or at risk of SZ when compared to healthy controls32,36,37,38,39,40,41,42,43,44,45 although results are not entirely consistent33,42,46. Importantly, speech coherence was also found to predict an SZ diagnosis and positive and negative symptoms with a good accuracy month in advance37,38. These findings collectively indicate that the use of NLP for analysis of speech coherence offers great potential to detect subjects who are at risk of developing psychosis, as well as to inform effective prevention and treatment regimens.
Surprisingly, no study has thus far analyzed the coherence of social media posts made by users who indicate that they suffer from psychotic symptoms. Hence, the aim of the present study was to examine whether reduced speech coherence typically found in patients suffering from SZ might also be evidenced in posts made in online forums for individuals suffering from psychosis. We first investigate whether coherence may be reduced in a forum on SZ, as only SZ reductions in coherence have been established using computational methods. As the control group, a forum on depression (r/depression) was considered. Mental health-related forums represent a more appropriate control group than non-mental health-related forums. The content of posts made in mental health-related forums and the users’ characteristics are likely more comparable. Furthermore, SZ and depression share a common negative symptomatology while FTD symptoms are more prevalent in SZ47. We expected that the coherence of posts made in r/schizophrenia would be lower than the coherence of posts made in r/depression.
We further analyzed coherence from posts in seven other subreddits on mental health (posttraumatic stress disorder (PTSD), attention deficit hyperactivity disorder (ADHD), anxiety, obsessive–compulsive disorder (OCD), autism, BD, dissociative identity disorder (DID)). Varying levels of psychotic symptoms have been found in these disorders. Psychotic symptoms are relatively well documented and most pronounced in BD48,49,50 and DID51,52. For PTSD53 and autism54 evidence for associations with psychotic symptoms has also been described, although to a lesser extent. While associations between psychotic symptoms and OCD, ADHD, anxiety disorders, and depression have been reported55,56,57,58, they seem to be less pronounced as compared to BD and DID. Thus, reduced speech coherence is typically found in SZ patients but might also be evidenced in individuals with psychotic symptoms having another primary diagnosis59,60,61. We therefore examined whether speech coherence varies across subreddits dedicated to mental health disorders which, to a greater or lesser extent, are associated with psychotic symptoms. We expected that higher rates of psychotic symptoms would coincide with lower coherence scores for the respective disorder categories. This type of analysis could inform more elaborated laboratory-based studies on speech coherence in clinically diagnosed participants suffering from various mental disorders.
As a reference for the coherence observed in the general population on Reddit, five popular non-mental health-related subreddits were chosen as a control group. The subreddits “r/self”, “r/relationship_advice”, “r/dating_advice”, “r/pettyrevenge” and “r/socialskills” were selected, because they contain posts similar in format to the mental health subreddit posts (mostly text paragraphs describing personal experience).
It is possible that discovered patterns of speech coherence are specific to posts made in mental health subreddits. One reason for this may be that users adapt their writing to other posts that they are reading, which could skew their writing further toward or away from coherence. To test whether such processes could influence the results, a second dataset comprising posts made in non-mental health-related subreddits was extracted.
Methods
As this study analyzed publicly available data, the approval of an ethics committee was not required. Data extraction, filtration, and preprocessing were performed in Python.
Data extraction
Posts were downloaded from a repository of Reddit submissions created by the Pushshift project62. Data provided by the Pushshift project has been extensively used in prior research6.
Dataset 1
All Reddit submissions made in the 36 months between the 1st of January 2021 and the 31st of December 2023 were downloaded. Subsequently, all submissions from the subreddits “r/Anxiety”, “r/OCD”, ‘r/depression”, ‘r/ADHD”, “r/autism”, “r/schizophrenia”, “r/ptsd”, “r/bipolar”, “r/DID” were extracted. In sum, 1,920,933 posts were extracted. Additionally, 300,000 non-deleted posts were randomly sampled from the control group. We refer to this dataset as dataset 1.
Dataset 2
The extraction of posts by control users and mental health-subreddit users in non-mental health-related subreddits followed a similar approach to Robertson et al.63. For each month in the year 2023, users submitting to each subreddit were extracted. If more than 1000 users were extracted, 1000 users were randomly sampled. Then, for the given month, all posts made by these users were extracted. Only posts that were not removed, deleted or empty were considered. Furthermore, posts made in popular mental health subreddits or the control forums were excluded. We refer to this dataset as dataset 2. In both datasets, only those posts starting a new thread (not comments to those posts) and only the body of text (not its header) were included in the analysis.
Data filtration
The presence of URLs was determined using the “urlextract” package and posts were discarded if they contained URLs. The “textblob” package, which is built on the “nltk” package, was used to tokenize the posts’ texts (divided into sentences). The function “.sentences” applied to a “TextBlob” object divides texts based on punctuation patterns but respects special cases, such as within-sentence punctuation-use (e.g., “Dr.”). Only posts that contained at least two sentences were submitted to preprocessing. Posts containing media content were only included if they also contained written text that conformed to the aforementioned criteria. The media content itself was ignored in those cases.
Data preprocessing
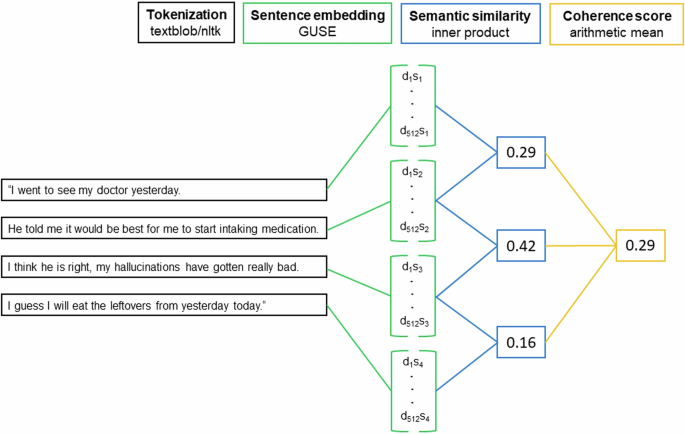
Like previous studies31,32,33, we operationalize coherence as the average semantic similarity between subsequent sentences. Coherence scores were calculated by first embedding all sentences of a post into 512-dimensional semantic space using GUSE64. Afterward, the inner product between the embeddings of subsequent sentences was calculated and averaged for each post32,33. The inner product of two sentence embeddings, which ranges from −1 (low) to 1 (high), represents their semantic similarity. Our approach to the calculation of coherence is similar to previous studies such as Iter et al.32 and Just et al.33. A graphical illustration of the coherence calculation process is given in Fig. 1.

Note. Paragraphs were first divided into sentences (tokenization). Afterward, sentences were embedded into 512-dimensional semantic space using Google’s Universal Sentence Encoder (GUSE) (Cer et al., 2018). The inner product of the embeddings of subsequent sentences represents their semantic similarity. The average of all sentence pairs’ similarity yielded the coherence scores. d1s1 denotes the first embedding dimension of the embedding vector of the first sentence. The narrative is quite coherent until the last sentence pair which is marked by a lower semantic similarity and thus represents a break in coherence.
Reddit forums impose idiosyncratic rules as to the content that may be posted. These rules are enforced through the deletion of posts that stand in violation of said rules. For example, in r/depression, users are explicitly asked to refrain from posting uplifting content, while no such rule exists in r/schizophrenia. We therefore deemed it necessary to control for other textual features, such as the posts’ emotional tone, that might systematically influence coherence scores. To this end, a sentiment analysis was performed using the “textblob” package. The sentiment analysis yields two values. The polarity, which will be referred to as emotional valence, is a measure ranging from −1 (negative) to 1 (positive) which captures the emotional tone of the texts. The subjectivity ranges from 0 (objective) to 1 (subjective) and captures the degree to which the text refers to personal experiences instead of impersonal facts.
Statistical analysis
The statistical analysis and plot creation were performed in R (R Core Team, 2013). Two-sided t-tests were used to test for differences between r/depression and r/schizophrenia on the covariates. Regression analyses were used to test for differences between groups on the coherence measure while controlling for the covariates. Lastly, post hoc pairwise comparisons were performed on the estimated marginal means from the regression models. To account for multiple tests, p-values were corrected using Tukey’s method. Statistical tests were considered significant at p-values below 0.05. Due to very small p-values and standard error estimates caused by large sample sizes, reported effect sizes should be taken into consideration.
Results
After data filtration dataset 1 consisted of 1,310,154 posts. Characteristics of the posts made in the different subreddits and the control group are shown in Table 1.
Comparison of r/schizophrenia and r/depression
Independent sample t-tests were performed to test for differences in r/depression and r/schizophrenia on the confounding variables. Posts in r/schizophrenia [M = 155.55, SD = 221.21] contained significantly fewer words than posts in r/depression [M = 204.24, SD = 182.76], t(37154) = 40.85, p < 0.001, 95% CI = 46.35–51.02, d = 0.22 [95% CI = 0.21–0.24]. Furthermore, posts in r/schizophrenia [M = 8.9, SD = 9.79] contained significantly fewer sentences than posts made in r/depression [M = 11.83, SD = 13.01], t(39300) = 45.12, p < 0.001, 95% CI = 2.8–3.05, d = 0.23 [95% CI = 0.22–0.24]. The sentence length was significantly lower in r/schizophrenia [M = 17.96, SD = 12.02] than in r/depression [M = 19.13, SD = 14.36], t(36885) = 14.92, p < 0.001, 95% CI = 1.01–1.32, d = 0.08[95% CI = 0.07–0.1]. The posts’ emotional tone were significantly more positive in r/schizophrenia [M = 0.03, SD = 0.19], when compared to r/depression [M = 0.001, SD = 0.17], t(33034) = 25.65, p < 0.001, 95% CI = 0.028–0.032], d = 0.17[95% CI = 0.16–0.19]. Lastly, posts in r/schizophrenia [M = 0.49, SD = 0.17] showed significantly less reference to subjective experience than posts in r/depression [M = 0.52, SD = 0.14], t(31657) = 27.39, p < 0.001, 95% CI = 0.027–0.031, d = 0.21[95% CI = 0.19–0.22]. As all comparisons yielded significant effects, all confounding variables were included in subsequent analyses.
An ordinary least square (OLS) multiple regression was fit to the data with coherence as the criterion and subreddit (0 = r/depression vs. 1 = r/schizophrenia), word count, sentence count, sentence length, emotional tone, and subjectivity as predictors. The predictors significantly explained variations in coherence, adj. R2 = 0.099, F(6, 269648) = 4958, p < 0.001. There were significant effects of the predictors subreddit, β = −0.021, t = −39.79, p < 0.001, η2p = 0.006, word count, β = 0.00003, t = 14.23, p < 0.001, η2p = 0.0008, sentence count, β = −0.0009, t = −28.13, p < 0.001, η2p = 0.003, sentence length, β = 0.002, t = 111.66, p < 0.001, η2p = 0.044, subjectivity, β = 0.028, t = 23.3, p < 0.001, η2p = 0.002, and emotional valence, β = −0.037, t = −38.93, p < 0.001, η2p = 0.006. The estimated marginal mean of coherence was lower in posts made in r/schizophrenia [M = 0.251, SE = 0.0002] than in r/depression [M = 0.272, SE = 0.0005]. The comparison yielded a Cohen’s d of 0.255 [95% CI = 0.242–0.268]. A post-hoc power analysis suggested that the achieved power of this comparison closely approaches 1.
Coherence across all subreddits
Next, the entire sample of subreddits was considered. An OLS multiple regression significantly explained variations in coherence, adj. R2 = 0.12, F(13,1025075) = 1077, p < 0.001. Again, the dummy-coded variable subreddit (0 = r/schizophrenia) significantly predicted the coherence scores while controlling for the confounding variables, all comparisons p < 0.001. The effects of the confounding variables were the same as in the previous regression model. Post hoc pairwise comparisons were performed on the estimated marginal means derived from the regression model. Multiple comparisons were adjusted using Tukey’s method. The results of the pairwise comparisons are listed in Table 2.
The lowest level of coherence was found in r/DID, followed by r/schizophrenia and r/autism. Medium-level coherence scores were found in r/ptsd and r/ADHD and r/bipolar. Coherence scores were the highest in the control group, followed by r/depression, r/Anxiety, and r/OCD. The estimated marginal means for the coherence of all ten subreddits and the post-hoc comparisons are shown in Fig. 2 and Table 2.

Note. Error bars represent the standard error of the estimated marginal means. The control group is composed of a sample of posts derived from the subreddits “r/self”, “r/relationship_advice”, “r/dating_advice”, “r/pettyrevenge” and “r/socialskills”.
Generalization to non-mental health-related subreddits
After data filtration, dataset 2 contained 353613 posts (Ncontrol = 121,897, NAnxiety = 35,108, Ndepression = 26,499, NOCD = 30,208, NADHD = 22,967, Nautism = 30,818, Nptsd = 30,533, Nschizophrenia = 23,026, Nbipolar = 20,152, NDID = 12,405). An OLS multiple regression was fit to the data with the same predictors and criterion as in the previous regressions. The regression model significantly explained variation in coherence scores, adj. R2 = 0.09, F(14,353598) = 2550, p < 0.001. All predictors significantly predicted the coherence scores. In contrast to the previous regression models, subjectivity now negatively predicted the coherence scores, β = −0.003, t = −23.45, p < 0.001, η2p = 0.002. All other regression coefficients retained their sign from the previous regressions. Based on this regression model, estimated marginal means were computed and used for pairwise comparisons. Multiple comparisons were adjusted for using Tukey’s method. Figure 3 and Table 3 depict the estimated marginal means, standard errors, and results of the pairwise comparisons. Coherence scores were the highest for the control group, r/Anxiety, r/depression, and r/OCD, and did not significantly differ from each other. Coherence scores were the lowest for r/bipolar and r/DID. Medium-level coherence scores emerged for r/ADHD, r/autism, r/ptsd, and r/schizophrenia, with no significant differences.

Note. Error bars represent the standard error of the estimated marginal means. The control group is composed of posts made by users of the subreddits “r/self”, “r/relationship_advice”, “r/dating_advice”, “r/pettyrevenge” and “r/socialskills”. The sample sizes after filtration were Ncontrol = 121,897, NAnxiety = 35,108, Ndepression = 26,499, NOCD = 30,208, NADHD = 22,967, Nautism = 30,818, Nptsd = 30,533, Nschizophrenia = 23,026, Nbipolar = 20,152, NDID = 12,405.
Discussion
We utilized NLP for the analysis of speech coherence, a pathological marker reflecting disorganized thinking, in posts gathered from the social media platform Reddit. NLP analysis revealed differences in the coherence of posts made in different forums related to mental health. Consistent with our hypothesis, coherence scores were lower in a forum on SZ than in a forum on depression. When analyzing coherence across a variety of psychopathology-related forum users, our analyses revealed the lowest coherence scores in DID and SZ forum users in dataset 1 and DID and BD forum users in dataset 2. In contrast, across both datasets, a relatively high level of coherence was detected for posts made by OCD, depression, and anxiety forum users. A control group reflective of the general Reddit user population showed the highest coherence scores.
Since the coherence score of a given text might be confounded by its length, emotional tone, and level of subjectivity, these measures were also extracted from posts and analyzed. The emotional valence of a post was negatively associated with the level of coherence. Additionally, for posts submitted to mental health subreddits, more personal/subjective stories were associated with a higher level of coherence. These findings align with previous research suggesting various prosocial consequences of coherent narration, such as increased social support, positive attitudes, and empathy toward narrators65,66,67. A central purpose of sharing personal experiences with others is the elicitation of social support68. Those users who share very negative personal experiences on Reddit probably do so because they seek peer support. Formulating a coherent post might aid them in this pursuit.
Our main analyses suggest an interesting trend whereby subreddits that showed the lowest coherence scores were geared toward disorders marked by more pronounced psychotic symptoms. In DID (>80% of patients52), BD (73.8% lifetime prevalence49), and PTSD (30-40% of combat veterans suffering from PTSD53), high rates of psychotic symptoms have been reported. In populations with autism spectrum disorder, a rate of 34.8% of comorbid SZ spectrum disorder diagnosis has been found54. In contrast, a heterogenous sample of subjects suffering from depressive and anxiety disorders (including PTSD), showed prevalence of psychotic symptoms of 27%58. In ADHD, no evidence of an increased risk of psychotic symptoms was found57. Only 14% of patients suffering from OCD were found to experience psychotic symptoms55. Speech incoherence may thus represent a psychopathological feature that varies in dependence on the degree of psychotic symptoms59,60,61. Consistent with this conclusion, symptoms of FTD, often equivalent to those found in SZ, have been found in BD and DID as well48,50,51.
Mental disorders are widely underrecognized and undertreated1. Diagnosis, prevention, and treatment programs based on large datasets obtained from online social media might offer promising solutions for challenges the mental healthcare field is facing2. Findings from laboratory studies indicate that speech coherence can be used to predict the onset of psychosis37,38. Our results provide the first evidence that incoherence may also be evidenced by social media posts. Future studies should investigate whether coherence may retain information about the presence, onset, or course of a disorder from the psychosis spectrum. Timely identification of high-risk individuals may allow for early-prevention and intervention programs that are more potent, less costly, and more widely available than interventions at advanced stages of the disorder such as inpatient treatment69,70. Because speech coherence analysis can be accompanied by automatic speech recognition technology without adverse effects on diagnostic accuracy71, such automated assessment pipelines might be a promising new diagnostic tool for future early prevention and treatment programs.
While several studies used NLP to examine linguistic features in social media posts made by subjects ostensibly suffering from psychosis8,17,18,19,20,21,22,23,24,25,26,27, this study explored the coherence of social media posts as an indicator of disorganization symptoms. A pronounced drawback of the present study is the lack of information on the users. Since the subreddits are open to all users irrespective of being “classified” as having mental health issues, the generalization of our findings to the clinical setting is not possible.
Additionally, with the rise and easy accessibility of generative large language models, the frequency of posts generated by machines (so-called “bots”) has increased. Consequently, the data quality of social media databases might become compromised and psychological investigations of real user behavior harder to perform. Information on user characteristics could help circumvent some of the limitations of our study. Additionally, information on the users’ clinical status or symptom severity might allow for more detailed analyses of psychosis-related incoherence in social media posts.
The coherence metric used here is related to a specific domain of FTD, namely tangentiality and derailment31. Given that many dimensions of FTD exist, future studies focusing on computational linguistic measures that correspond to other dimensions of FTD would be highly valuable. Notably, research on FTD and coherence has been predominantly performed on speech samples rather than written text31,33. Although written text is a more curated form of language production than speech, social media posts are arguably less curated than other written material. While our findings indicate that certain psychosis-related linguistic alterations are evidenced in written material, it still needs to be addressed how our findings correspond to data extracted from speech.
Lastly, we wish to emphasize that in order to use data from social media for clinical diagnosis and treatment, certain ethical and methodological considerations need to be taken into account. This is important to prevent users from being misidentified as being at high risk for a mental disorder or being assigned to an inappropriate treatment. Any sort of initial screening based on social media activity should be considered preliminary. Prior to the use of big social media data for clinical purposes, we need to ensure that collection methods are transparent, respecting user privacy rights, that findings are robust and interpreted in line with psychopathological models and that no harm is caused.
Conclusion
We show that speech incoherence may be evidenced by social media posts. The most striking reduction in coherence emerged for forums on DID, SZ, and BD, the three disorders most commonly associated with psychotic and FTD symptomatology.
Data availability
Data are available from the first author upon reasonable request.
Code availability
Code written for the purpose of this study is available from the first author upon reasonable request. For data extraction and preprocessing python (3.9.17), including the packages “numpy” (1.25.2), “pandas” (2.0.3), “tensorflow_hub” (0.15.0), “urlextract” (1.9.0), “textblob” (0.17.1) was used. For the statistical analysis R (4.3.1), including the packages “readxl” (1.4.3), “ggplot2” (3.4.3), “emmeans” (1.10.1), “car” (3.1-2), “stats” (4.3.1), “rstatix” (0.7.2), was used.
References
-
Lecrubier, Y. Widespread underrecognition and undertreatment of anxiety and mood disorders: results from 3 European studies. J. Clin. Psychiatry 68, 36–41 (2007).
-
Bucci, S., Schwannauer, M. & Berry, N. The digital revolution and its impact on mental health care. Psychol. Psychother. Theory Res. Pract. 92, 277–297 (2019).
-
Naslund, J. A., Bondre, A., Torous, J. & Aschbrenner, K. A. Social media and mental health: benefits, risks, and opportunities for research and practice. J. Technol. Behav. Sci. 5, 245–257 (2020).
-
Reddit. Reddit by the numbers. (2024).
-
Boettcher, N. Studies of depression and anxiety using Reddit as a data source: scoping review. JMIR Ment. Health 8, 29487 (2021).
-
Proferes, N., Jones, N., Gilbert, S., Fiesler, C. & Zimmer, M. Studying Reddit: a systematic overview of disciplines, approaches, methods, and ethics. Soc. Media Soc. 7, 20563051211019004 (2021).
-
Insel, T. R. Digital phenotyping: technology for a new science of behavior. J. Am. Med. Assoc. 318, 1215–1216 (2017).
-
Lejeune, A., Robaglia, B. M., Walter, M., Berrouiguet, S. & Lemey, C. Use of social media data to diagnose and monitor psychotic disorders: systematic review. J. Med. Internet Res. 24, 36986 (2022).
-
Guntuku, S. C., Yaden, D. B., Kern, M. L., Ungar, L. H. & Eichstaedt, J. C. Detecting depression and mental illness on social media: an integrative review. Curr. Opin. Behav. Sci. 18, 43–49 (2017).
-
Monti, C., Aiello, L. M., Francisci Morales, G. & Bonchi, F. The language of opinion change on social media under the lens of communicative action. Sci. Rep. 12, 17920 (2022).
-
Zhang, T., Schoene, A. M., Ji, S. & Ananiadou, S. Natural language processing applied to mental illness detection: a narrative review. NPJ Digit. Med. 5, 1–13 (2022).
-
Graves, R. L. et al. Thematic analysis of Reddit content about buprenorphine-naloxone using manual annotation and natural language processing techniques. J. Addict. Med. 16, 454–460 (2022).
-
Liu, T. et al. Detecting symptoms of depression on Reddit. in Proceedings of the 15th ACM Web Science Conference 2023 174–183 (2023).
-
Shen, J. H. & Rudzicz, F. Detecting anxiety through Reddit. in Proceedings of the Fourth Workshop on Computational Linguistics and Clinical Psychology—From Linguistic Signal to Clinical Reality 58–65 (2017).
-
Alambo, A. et al. Question answering for suicide risk assessment using Reddit. in 2019 IEEE 13th International Conference on Semantic Computing (ICSC 468–473 (IEEE, 2019).
-
Sekulić, I. & Gjurković, M. & Šnajder, J. Not Just Depressed: Bipolar Disorder Prediction on Reddit (2018).
-
Bae, Y. J., Shim, M. & Lee, W. H. Schizophrenia detection using machine learning approach from social media content. Sensors 21, 5924 (2021).
-
Birnbaum, M. et al. O9. 2. Identifying psychotic symptoms and predicting relapse through social media. Schizophr. Bull. 44, 100 (2018).
-
Birnbaum, M. L., Ernala, S. K., Rizvi, A. F., Choudhury, M. & Kane, J. M. A collaborative approach to identifying social media markers of schizophrenia by employing machine learning and clinical appraisals. J. Med. Internet Res. 19, 7956 (2017).
-
Dinev, M., Belousov, M., Morris, R., Berry, N. & Nenadic, G. Using Twitter to mine sleep related information from people who declare a diagnosis of a psychotic disorder. Int. J. Popul. Data Sci. 1, 349 (2017).
-
Ernala, S. K., Rizvi, A. F., Birnbaum, M. L., Kane, J. M. & Choudhury, M. Linguistic markers indicating therapeutic outcomes of social media disclosures of schizophrenia. Proc. ACM Hum. Comput. Interact. 1, 1–27 (2017).
-
Joseph, S. M., Citraro, S., Morini, V., Rossetti, G. & Stella, M. Cognitive network neighborhoods quantify feelings expressed in suicide notes and Reddit mental health communities. Phys. Stat. Mech. Appl. 610, 128336 (2023).
-
Kim, J., Lee, J., Park, E. & Han, J. A deep learning model for detecting mental illness from user content on social media. Sci. Rep. 10, 11846 (2020).
-
Lyons, M., Bootes, E., Brewer, G., Stratton, K. & Centifanti, L. COVID-19 spreads round the planet, and so do paranoid thoughts. A qualitative investigation into personal experiences of psychosis during the COVID-19 pandemic. Curr. Psychol. 42, 1–10 (2021).
-
McManus, K., Mallory, K., Goldfeder, R. L. & Tatum, J. D. Mining Twitter data to improve detection of schizophrenia. AMIA Jt Summits Transl. Sci. Proc. 2015, 122–126 (2015).
-
Mitchell, M., Hollingshead, K. & Coppersmith, G. Quantifying the language of schizophrenia in social media. in Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality 11–20 (2015).
-
Zomick, J., Levitan, S. I. & Serper, M. Linguistic analysis of schizophrenia in Reddit posts. in Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology 74–83 (2019).
-
DataReportal, M. & Social, W. A. Number of internet and social media users worldwide as of January 2024 (in billions) [Graph. in Statista (2024).
-
Hitczenko, K., Mittal, V. A. & Goldrick, M. Understanding language abnormalities and associated clinical markers in psychosis: the promise of computational methods. Schizophr. Bull. 47, 344–362 (2021).
-
van Schuppen, S. L., Krieken, K., Claassen, S. A. & Sanders, J. Perspective-taking and intersubjectivity in oral narratives of people with a schizophrenia diagnosis: a cognitive linguistic viewpoint analysis. Cogn. Linguist. 34, 197–229 (2023).
-
Bilgrami, Z. R. et al. Construct validity for computational linguistic metrics in individuals at clinical risk for psychosis: associations with clinical ratings. Schizophr. Res. 245, 90–96 (2022).
-
Iter, D., Yoon, J. & Jurafsky, D. Automatic detection of incoherent speech for diagnosing schizophrenia. in Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic 136–146 (2018).
-
Just, S. et al. Coherence models in schizophrenia. in Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology 126–136 (2019).
-
Andreasen, N. C. & Grove, W. M. Thought, language, and communication in schizophrenia: diagnosis and prognosis. Schizophr. Bull. 12, 348–359 (1986).
-
Bleuler, E. Dementia Praecox or the Group of Schizophrenias. International Universities Press (1950).
-
Bar K. et al. Semantic Characteristics of Schizophrenic Speech. arXiv preprint arXiv:1904.07953 (2019).
-
Bedi, G. et al. Automated analysis of free speech predicts psychosis onset in high-risk youths. Npj Schizophr. 1, 1–7 (2015).
-
Corcoran, C. M. et al. Prediction of psychosis across protocols and risk cohorts using automated language analysis. World Psychiatry 17, 67–75 (2018).
-
Corona-Hernández, H., Boer, J. N., Brederoo, S. G., Voppel, A. E. & Sommer, I. E. C. Assessing coherence through linguistic connectives: analysis of speech in patients with schizophrenia-spectrum disorders. Schizophr. Res. 259, 48–58 (2023).
-
Elvevåg, B., Foltz, P. W., Weinberger, D. R. & Goldberg, T. E. Quantifying incoherence in speech: an automated methodology and novel application to schizophrenia. Schizophr. Res. 93, 304–316 (2007).
-
Morgan, S. E. et al. Natural Language Processing markers in first episode psychosis and people at clinical high-risk. Transl. Psychiatry 11, 630 (2021).
-
Parola, A. et al. Speech disturbances in schizophrenia: assessing cross-linguistic generalizability of NLP automated measures of coherence. Schizophr. Res. 259, 59–70 (2023).
-
Ryazanskaya, G. & Khudyakova, M. Automated analysis of discourse coherence in schizophrenia: approximation of manual measures. LREC 2020 Lang. Resour. Eval. Conf. 98, 101 (2020).
-
Sarzynska-Wawer, J. et al. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 304, 114135 (2021).
-
Voppel, A. E., Boer, J. N., Brederoo, S. G., Schnack, H. G. & Sommer, I. E. C. Quantified language connectedness in schizophrenia-spectrum disorders. Psychiatry Res. 304, 114130 (2021).
-
Haas, S. S. et al. Linking language features to clinical symptoms and multimodal imaging in individuals at clinical high risk for psychosis. Eur. Psychiatry 63, 72 (2020).
-
Roche, E., Creed, L., MacMahon, D., Brennan, D. & Clarke, M. The epidemiology and associated phenomenology of formal thought disorder: a systematic review. Schizophr. Bull. 41, 951–962 (2015).
-
Mutlu, E., Gürkan, Ş., Göka, E. & Yağcioğlu, A. E. A. Comparison of formal thought disorder in the acute episode of schizophrenia and manic episode of bipolar affective disorder. Turk. J. Psychiatry 33, 223–232 (2022).
-
van Bergen, A. H. et al. The characteristics of psychotic features in bipolar disorder. Psychol. Med. 49, 2036–2048 (2019).
-
Yalincetin, B. et al. Formal thought disorder in schizophrenia and bipolar disorder: a systematic review and meta-analysis. Schizophr. Res. 185, 2–8 (2017).
-
Dorahy, M. J. et al. A comparison between auditory hallucinations, interpretation of voices, and formal thought disorder in dissociative identity disorder and schizophrenia spectrum disorders. J. Clin. Psychol. 79, 2009–2022 (2023).
-
Foote, B. & Park, J. Dissociative identity disorder and schizophrenia: differential diagnosis and theoretical issues. Curr. Psychiatry Rep. 10, 217–222 (2008).
-
Lindley, S. E., Carlson, E. & Sheikh, J. Psychotic symptoms in posttraumatic stress disorder. CNS Spectr. 5, 52–57 (2000).
-
Chisholm, K., Lin, A., Abu-Akel, A. & Wood, S. J. The association between autism and schizophrenia spectrum disorders: a review of eight alternate models of co-occurrence. Neurosci. Biobehav. Rev. 55, 173–183 (2015).
-
Eisen, J. L. & Rasmussen, S. A. Obsessive compulsive disorder with psychotic features. J. Clin. Psychiatry 54, 373–379 (1993).
-
Palermo, S., Marazziti, D., Baroni, S., Barberi, F. M. & Mucci, F. The relationships between obsessive-compulsive disorder and psychosis: an unresolved issue. Clin. Neuropsychiatry 17, 149 (2020).
-
Vitiello, B. et al. Psychotic symptoms in attention-deficit/hyperactivity disorder: an analysis of the MTA database. J. Am. Acad. Child Adolesc. Psychiatry 56, 336–343 (2017).
-
Wigman, J. T. et al. Evidence that psychotic symptoms are prevalent in disorders of anxiety and depression, impacting on illness onset, risk, and severity—implications for diagnosis and ultra–high risk research. Schizophr. Bull. 38, 247–257 (2012).
-
Kircher, T., Bröhl, H., Meier, F. & Engelen, J. Formal thought disorders: from phenomenology to neurobiology. Lancet Psychiatry 5, 515–526 (2018).
-
Lott, P. R., Guggenbühl, S., Schneeberger, A., Pulver, A. E. & Stassen, H. H. Linguistic analysis of the speech output of schizophrenic, bipolar, and depressive patients. Psychopathology 35, 220–227 (2002).
-
Stein, F. et al. State of illness-dependent associations of neuro-cognition and psychopathological syndromes in a large transdiagnostic cohort. J. Affect. Disord. 324, 589–599 (2023).
-
Baumgartner, J., Zannettou, S., Keegan, B., Squire, M. & Blackburn, J. The pushshift Reddit dataset. Proc. Int. AAAI Conf. Web Soc. Media 14, 830–839 (2020).
-
Robertson, C., Carney, J. & Trudell, S. Language about the future on social media as a novel marker of anxiety and depression: a big-data and experimental analysis. Curr. Res. Behav. Sci. 4, 100104 (2023).
-
Cer, D. et al. Universal sentence encoder for English. in Proceedings of the 2018 Conference On Empirical Methods In Natural Language Processing: System Demonstrations 169–174 (2018).
-
Vanaken, L. & Hermans, D. Be coherent and become heard: the multidimensional impact of narrative coherence on listeners’ social responses. Mem. Cogn. 49, 276–292 (2021).
-
Vanaken, L., Bijttebier, P., Fivush, R. & Hermans, D. Narrative coherence predicts emotional well-being during the COVID-19 pandemic: a two-year longitudinal study. Cogn. Emot. 36, 70–81 (2022).
-
Vanaken, L., Bijttebier, P. & Hermans, D. I like you better when you are coherent. Narrating autobiographical memories in a coherent manner has a positive impact on listeners’ social evaluations. PLoS One 15, 0232214 (2020).
-
Bluck, S. Autobiographical memory: Exploring its functions in everyday life. Memory 11, 113–123 (2003).
-
Colizzi, M., Lasalvia, A. & Ruggeri, M. Prevention and early intervention in youth mental health: is it time for a multidisciplinary and trans-diagnostic model for care? Int. J. Ment. Health Syst. 14, 1–14 (2020).
-
Le, L. K. D. et al. Cost-effectiveness evidence of mental health prevention and promotion interventions: a systematic review of economic evaluations. PLoS Med. 18, 1003606 (2021).
-
Ciampelli, S., Voppel, A. E., Boer, J. N., Koops, S. & Sommer, I. E. C. Combining automatic speech recognition with semantic natural language processing in schizophrenia. Psychiatry Res. 325, 115252 (2023).
Acknowledgements
This work was supported by grant No. ZL 59/4-1 and 59/5-1 to A.Z. from the German Research Foundation (Deutsche Forschungsgemeinschaft).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
L.P. and A.Z. conceptualized the study. L.P. curated the data and performed the formal analysis. L.P. and A.Z. interpreted the data and wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Plank, L., Zlomuzica, A. Reduced speech coherence in psychosis-related social media forum posts.
Schizophr 10, 60 (2024). https://doi.org/10.1038/s41537-024-00481-1
-
Received:
-
Accepted:
-
Published:
-
DOI: https://doi.org/10.1038/s41537-024-00481-1
This post was originally published on this site be sure to check out more of their content



